建设银行租房网站网络公司网络推广
一、简单介绍
Hadoop最早诞生于Cutting于1998年左右开发的一个全文文本搜索引擎
Lucene,这个搜索引擎在2001年成为Apache基金会的一个子项目,也是 ElasticSearch等重要搜索引擎的底层基础。
项目官方:https://hadoop.apache.org/
二、Linux环境搭建
首先准备三台Linux服务器,预装CentOS7。三台服务器之间需要网络互通。本地测试环境的IP地址分别为:192.168.2.128,192.168.2.129,
192.168.2.130
内存配置建议不低于4G,硬盘空间建议不低于50G。
1、配置hosts
vi /etc/hosts
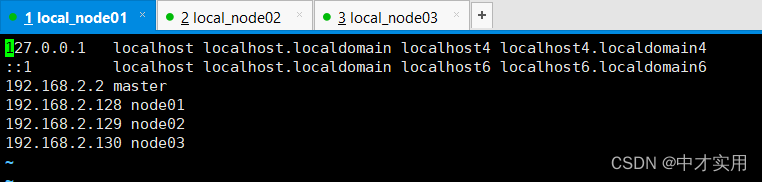
这里是给每个机器配置一个机器名。后续集群中都会通过机器名进行配 置管理,而不会再关注IP地址。
2、关闭防火墙
Hadoop集群节点之间需要进行频繁复杂的网络交互,在实验环境建议关闭防火墙。生产环境下,可以根据情况选择是按照端口配置复杂的防火墙规则或者关闭内部防火墙,使用堡垒机进行统一防护。
systemctl stop firewalld
systemctl disable firewalld.service
3、配置SSH免密
1、在node01下执行,一路回车(四次)
ssh-keygen -t rsa
2、然后在 node01上执行
ssh-copy-id node01
3、输入 yes,然后回车,接着输入 root 密码,然后会得到如下日志

4、验证一下,在 node01节点执行
ssh node01

5、在node02,node03节点分别执行上述四个步骤(注意节点名称的替换)
6、最后分别在node01上执行
ssh-copy-id node02
ssh-copy-id node03
在node02上执行
ssh-copy-id node01
ssh-copy-id node03
同理,在node03上执行
ssh-copy-id node01
ssh-copy-id node02
7、查看是否成功免密登录

4、安装JDK
尽量不要使用Linux自带的OpenJDK。
卸载指令 :rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
自行下载JDK jdk-8u212-linux-x64.tar.gz。解压到/usr/java目录。
最后配置一下jdk的环境变量
(注:node01、node02、node03三个节点都按装部署jdk环境)
export JAVA_HOME=/usr/java/jdk1.8.0_291
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin

5、创建用户(可选)
这里直接使用系统提供的root用户来直接进行操作。
通常在正是的生产环境中,root用户都是要被严格管控的,这时就需要单独创建一个用户来管理这些应用
三、Hadoop集群搭建
1、版本选择
这里选择的是3.2.2版本 hadoop-3.2.2.tar.gz ,下载地址:https://hadoop.apache.org/release/3.2.2.html
2、 集群机器角色规划

其中,HDFS是一个分布式的文件系统,主要负责文件的存储。由NameNode、Secondary
NameNode和DataNode三种节点组成。HDFS上的文件,会以文件块(Block)的形式存储到不同的DataNode节点当中。NameNode则用来存储文件的相关元数据,比如文件名、文件目录结果、文件的块列表等。然后SecondaryNameNode则负责每隔一段时间对NameNode上的元数据进行备份。
Yarn是一个资源调度的工具,负责对服务器集群内的计算资源,主要是CPU和内存,进行合理的分配与调度。由ResourceManager和NodeManager两种节点组成。ResourceManager负责对系统内的计算资源进行调度分配,将计算任务分配到具体的NodeManger节点上执行。而NodeManager则负责具体的计算任务执行。
3、按装Hadoop
1、在所有虚拟机根目录下新建文件夹export,export文件夹中新建data、servers和software文件
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software
2、解压Hadoop安装包
cd /export/software
tar -zxvf hadoop-3.2.2.tar.gz -C /export/servers/
3、配置hadoop环境变量
打开配置文件
vi /etc/profile
配置文件最后追加的配置
export HADOOP_HOME=/export/servers/hadoop-3.2.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置文件生效
source /etc/profile
4、查看是否配置成功
hadoop version

4、Hadoop集群配置
配置前先介绍一下配置文件
以下所有的配置文件都在hadoop安装目录下etc文件中,路径如下:
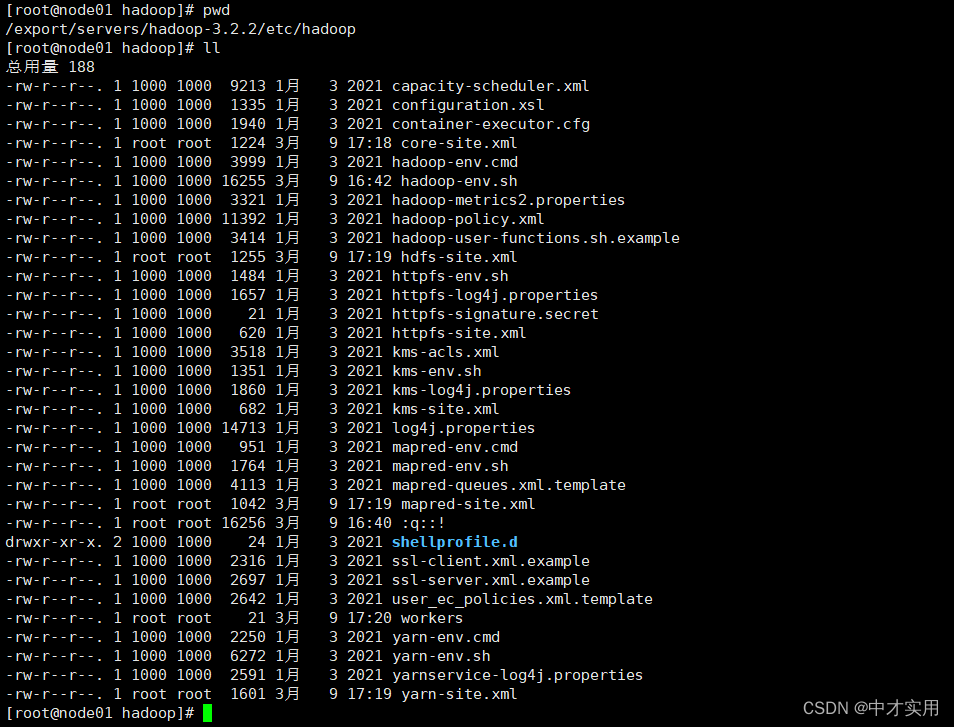
需要配置的文件有以下6个
1、配置hadoop-env.sh文件
vi hadoop-env.sh
#找到相应位置添加这段
export JAVA_HOME=/usr/java/jdk1.8.0_291

2、配置core-site.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://node01:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/export/servers/hadoop-3.2.2/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为当前操作系统用户 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property>
</configuration>
3、配置hdfs-site.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!-- NameNode web 端访问地址--><property><name>dfs.namenode.http-address</name><value>node01:9870</value></property><!-- 2NameNode web 端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>node03:9868</value></property><!-- 备份数量 --><property><name>dfs.replication</name><value>2</value></property><!-- 打开webhdfs --><property><name>dfs.webhdfs.enabled</name><value>true</value></property>
</configuration>4、配置yarn-site.xml文件
<?xml version="1.0"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
-->
<configuration><!-- 指定 MR 走 shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定 ResourceManager 的地址--><property><name>yarn.resourcemanager.hostname</name><value>node02</value></property><!-- 环境变量的继承 跑示例时要用到--><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志聚集服务器地址 --><property><name>yarn.log.server.url</name><value>http://node01:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为 7 天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>
</configuration>5、配置mapred-site.xml文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration><!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 历史服务器 web 端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>node01:19888</value></property>
</configuration>6、配置workers文件
node01
node02
node03
7、将配置完成后的hadoop整体分发到另外的节点(完成node02、node03两个节点和node01相同的配置)
scp ~/.bash_profile root@node02:~
scp -r /export/servers/hadoop-3.2.2 root@node02:/export/servers/hadoop-3.2.2
scp ~/.bash_profile root@node03:~
scp -r /export/servers/hadoop-3.2.2 root@node03:/export/servers/hadoop-3.2.2
5、启动Hadoop集群
1、先启动hdfs服务(在node01上启动NameNode、DataNode)
第一次启动hdfs服务时,需要先对NameNode进行格式化。在NameNode所
在的node01机器,执行hadoop namenode -format执行,完成初始化。初始化完成后,会在 /export/servers/hadoop-3.2.2/data/dfs/name/current目录下创建一个NameNode的镜像。
接下来可以尝试启动hdfs了。 hadoop的启动脚本在hadoop下的sbin目录
下。 start-dfs.sh就是启动hdfs的脚本。
当前版本hadoop如果不创建单独用户,而是直接使用root用户启动,会报错。这时就需要添加之前配置的HDFS_NAMENODE_USER 等几个环境变量。
打开配置文件vi /etc/profile在最后追加如下内容,保存退出source /etc/profile(node02、node03节点不要忘记配置)
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/export/servers

2、接下来启动Yarn(node02上启动ResourceManager、DataNoda)
注意下在yarn-site.xml中配置了日志聚合,将yarn的执行日志配置到了
hdfs上。所以yarn建议在hdfs后启动。当然,在生产环境下需要评估这
种日志方式是否合适。

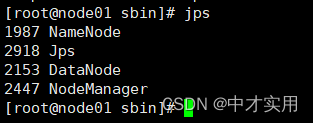
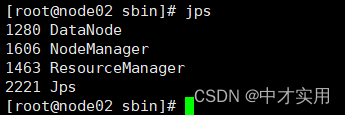
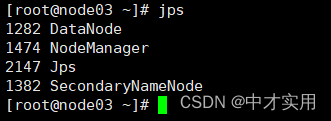
3、查看各个节点服务启动进程
DataNode: 数据节点。
NameNode 名称服务;
SecondaryNameNode 备份名称服务
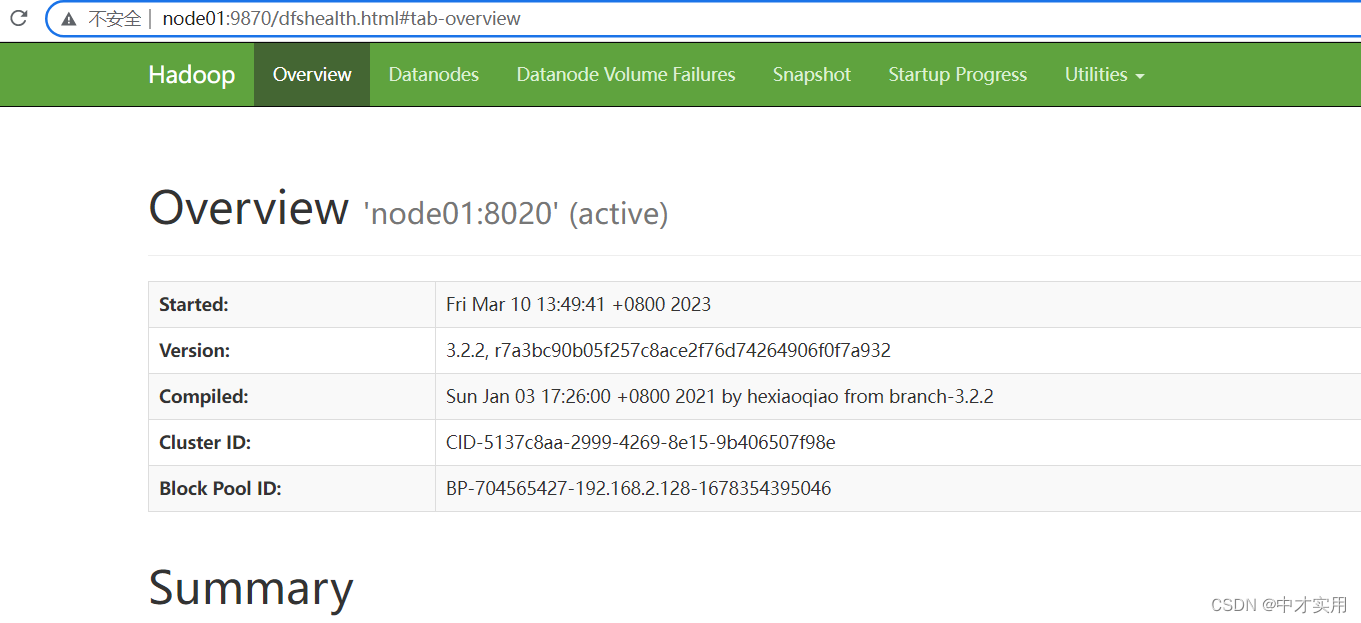
4、访问HDFS的Web页面
配置window下的host文件 C:\Windows\System32\drivers\etc打开hosts文件
192.168.2.128 node01
192.168.2.129 node02
192.168.2.130 node03
http://node01:9870/
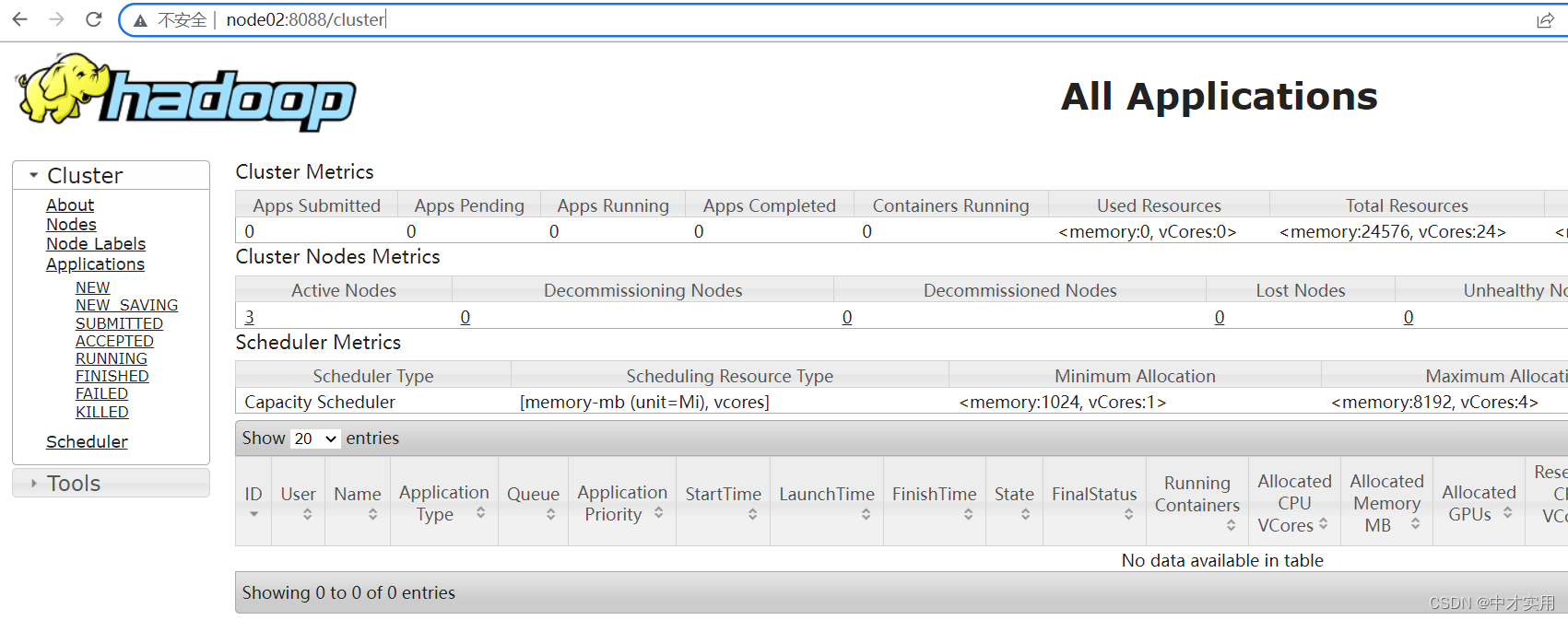
5、访问yarn的管理页面
http://node02:8088/
hadoop集群环境配置搭建完成!