wordpress企业网站制作驾校推广网络营销方案
场景:在局域网内,需要将多个机器网卡上抓到的数据包同步到一个机器上。
原有方案:tcpdump -w 写入文件,然后定时调用 rsync 进行同步。
改造方案:使用 Go 重写这个抓包逻辑及同步逻辑,直接将抓到的包通过网络发送至服务端,由服务端写入,这样就减少了一次落盘的操作。
构造一个 pcap 文件很简单,需要写入一个 pcap文件头,后面每一条数据增加一个元数据进行描述。使用 pcapgo 即可实现这个功能,p.buffer[:ci.CaptureLength] 为抓包的数据。
ci := gopacket.CaptureInfo{CaptureLength: int(n),Length: int(n),Timestamp: time.Now(),
}
if ci.CaptureLength > len(p.buffer) {ci.CaptureLength = len(p.buffer)
}
w.WritePacket(ci, p.buffer[:ci.CaptureLength])为了通过区分是哪个机器过来的数据包需要增加一个 Id,算上元数据和原始数据包,表达结构如下
// from github.com/google/gopacket
type CaptureInfo struct {// Timestamp is the time the packet was captured, if that is known.Timestamp time.Time `json:"ts" msgpack:"ts"`// CaptureLength is the total number of bytes read off of the wire.CaptureLength int `json:"cap_len" msgpack:"cap_len"`// Length is the size of the original packet. Should always be >=// CaptureLength.Length int `json:"len" msgpack:"len"`// InterfaceIndexInterfaceIndex int `json:"iface_idx" msgpack:"iface_idx"`
}type CapturePacket struct {CaptureInfoId uint32 `json:"id" msgpack:"id"`Data []byte `json:"data" msgpack:"data"`
}有一个细节待敲定,抓到的包使用什么结构发送至服务端?json/msgpack/自定义格式?
json/msgpack 都有对应的规范,通用性强,不容易出 BUG,性能会差一点。自定义格式相比 json/msgpack 而言,可以去掉不必要的字段,连 key 都可以不用在序列化中出现,并且可以通过一些优化减少内存的分配,缓解gc压力。
自定义二进制协议优化思路如下
-
CaptureInfo/Id 字段直接固定N个字节表示,对于 CaptureLength/Length 可以直接使用 2 个字节来表达,Id 如果数量很少使用 1 个字节来表达都可以
-
内存复用Encode 逻辑内部不分配内存,这样直接写入外部的 buffer,如果外部 buffer 是同步操作的话,整个逻辑 0 内存分配Decode 内部不分配内存,只解析元数据和复制 Data 切片,如果外部是同步操作,同样整个过程 0 内存分配如果是异步操作,那么在调用 Encode/Decode 的地方对 Data 进行复制,这里可以使用 sync.Pool 进行优化,使用四个 sync.Pool 分别分配 128/1024/8192/65536 中数据
sync.Pool 的优化点有两个
-
异步操作下每个 Packet.Data 都需要有自己的空间,不能进行复用,使用 sync.Pool 来构造属于 Packet 的空间
-
元数据序列化固定字节长度的 buffer,使用 make 或者数组都会触发 gc
func acquirePacketBuf(n int) ([]byte, func()) {var (buf []byteputfn func())if n <= CapturePacketMetaLen+128 {smallBuf := smallBufPool.Get().(*[CapturePacketMetaLen + 128]byte)buf = smallBuf[:0]putfn = func() { smallBufPool.Put(smallBuf) }} else if n <= CapturePacketMetaLen+1024 {midBuf := midBufPool.Get().(*[CapturePacketMetaLen + 1024]byte)buf = midBuf[:0]putfn = func() { midBufPool.Put(midBuf) }} else if n <= CapturePacketMetaLen+8192 {largeBuf := largeBufPool.Get().(*[CapturePacketMetaLen + 8192]byte)buf = largeBuf[:0]putfn = func() { largeBufPool.Put(largeBuf) }} else {xlargeBuf := xlargeBufPool.Get().(*[CapturePacketMetaLen + 65536]byte)buf = xlargeBuf[:0]putfn = func() { xlargeBufPool.Put(xlargeBuf) }}return buf, putfn
}func (binaryPack) EncodeTo(p *CapturePacket, w io.Writer) (int, error) {buf := metaBufPool.Get().(*[CapturePacketMetaLen]byte)defer metaBufPool.Put(buf)binary.BigEndian.PutUint64(buf[0:], uint64(p.Timestamp.UnixMicro()))...return nm + nd, err
}数据包构造大小(By 通义千问)
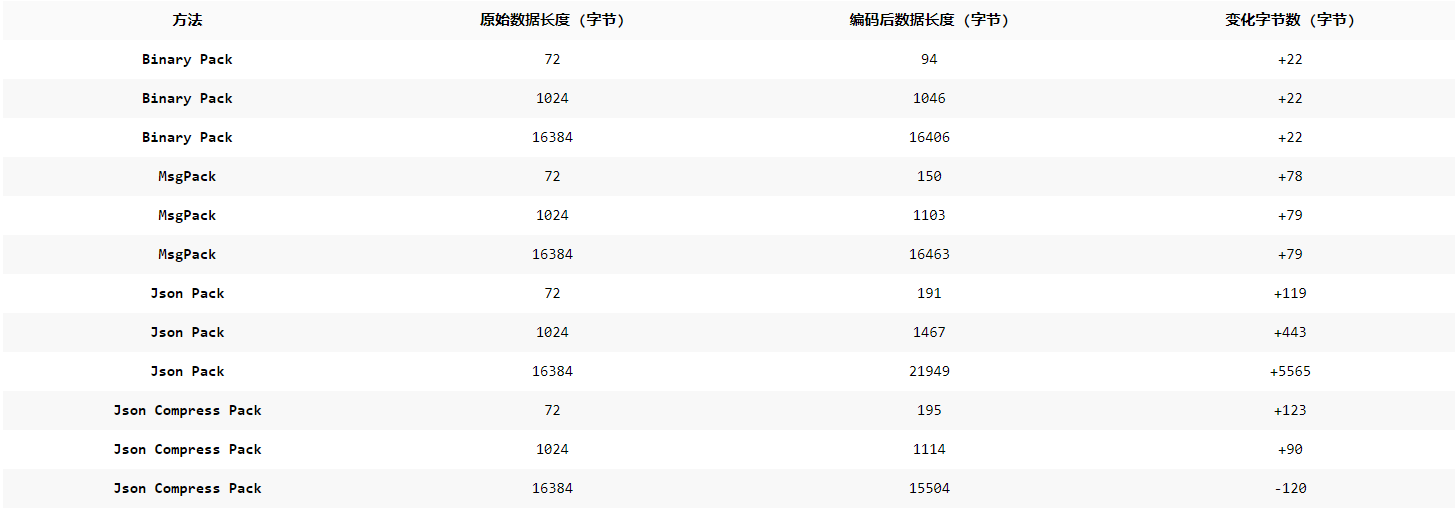
分析
-
Binary Pack:
对于较小的数据(72字节),编码后增加了22字节。
对于较大的数据(16384字节),编码后增加了22字节。
总体来看,Binary Pack的编码效率较高,增加的字节数相对较少。
-
MsgPack:
对于较小的数据(72字节),编码后增加了78字节。
对于较大的数据(16384字节),编码后增加了79字节。
MsgPack的编码效率在小数据量时不如Binary Pack,但在大数据量时仍然保持较高的效率。
-
Json Pack:
对于较小的数据(72字节),编码后增加了119字节。
对于较大的数据(16384字节),编码后增加了5565字节。
Json Pack的编码效率较低,特别是对于大数据量,增加的字节数较多。
-
Json Compress Pack:
对于较小的数据(72字节),编码后增加了123字节。
对于较大的数据(16384字节),编码后增加了120字节。
Json Compress Pack在小数据量时增加的字节数较多,但在大数据量时增加的字节数较少,表明压缩效果较好。
通过这个表格,你可以更直观地看到不同数据打包方法在不同数据量下的表现。希望这对你有帮助!
Benchmark
json
可以看到使用 buffer 进行复用提升比较明显,主要还是减少内存分配带来的提升。
BenchmarkJsonPack/encode#72-20 17315143 647.1 ns/op 320 B/op 3 allocs/op
BenchmarkJsonPack/encode#1024-20 4616841 2835 ns/op 1666 B/op 3 allocs/op
BenchmarkJsonPack/encode#16384-20 365313 34289 ns/op 24754 B/op 3 allocs/op
BenchmarkJsonPack/encode_with_buf#72-20 24820188 447.4 ns/op 128 B/op 2 allocs/op
BenchmarkJsonPack/encode_with_buf#1024-20 13139395 910.6 ns/op 128 B/op 2 allocs/op
BenchmarkJsonPack/encode_with_buf#16384-20 1414260 8472 ns/op 128 B/op 2 allocs/op
BenchmarkJsonPack/decode#72-20 8699952 1364 ns/op 304 B/op 8 allocs/op
BenchmarkJsonPack/decode#1024-20 2103712 5605 ns/op 1384 B/op 8 allocs/op
BenchmarkJsonPack/decode#16384-20 159140 73101 ns/op 18664 B/op 8 allocs/opmsgpack
同样看到使用 buffer 进行复用的提升,和 json 的分水岭大概在 1024 字节左右,超过这个大小 msgpack 速度快很多,并且在解析的时候内存占用不会随数据进行增长。
BenchmarkMsgPack/encode#72-20 10466427 1199 ns/op 688 B/op 8 allocs/op
BenchmarkMsgPack/encode#1024-20 6599528 2132 ns/op 1585 B/op 8 allocs/op
BenchmarkMsgPack/encode#16384-20 1478127 8806 ns/op 18879 B/op 8 allocs/op
BenchmarkMsgPack/encode_with_buf#72-20 26677507 388.2 ns/op 192 B/op 4 allocs/op
BenchmarkMsgPack/encode_with_buf#1024-20 31426809 400.2 ns/op 192 B/op 4 allocs/op
BenchmarkMsgPack/encode_with_buf#16384-20 22588560 494.5 ns/op 192 B/op 4 allocs/op
BenchmarkMsgPack/decode#72-20 19894509 654.2 ns/op 280 B/op 10 allocs/op
BenchmarkMsgPack/decode#1024-20 18211321 664.0 ns/op 280 B/op 10 allocs/op
BenchmarkMsgPack/decode#16384-20 13755824 769.1 ns/op 280 B/op 10 allocs/opjson压缩
在内网的情况下,带宽不是问题,这个压测结果直接被 Pass
BenchmarkJsonCompressPack/encode#72-20 19934 709224 ns/op 1208429 B/op 26 allocs/op
BenchmarkJsonCompressPack/encode#1024-20 17577 766349 ns/op 1212782 B/op 26 allocs/op
BenchmarkJsonCompressPack/encode#16384-20 11757 860371 ns/op 1253975 B/op 25 allocs/op
BenchmarkJsonCompressPack/decode#72-20 490164 28972 ns/op 42048 B/op 15 allocs/op
BenchmarkJsonCompressPack/decode#1024-20 187113 71612 ns/op 47640 B/op 23 allocs/op
BenchmarkJsonCompressPack/decode#16384-20 35790 346580 ns/op 173352 B/op 30 allocs/op自定义二进制协议
对于序列化和反序列化在复用内存后,速度的提升非常明显,在同步的操作下,能做到 0 字节分配。异步场景下,使用 sync.Pool 内存固定字节分配(两个返回值在堆上分配)
BenchmarkBinaryPack/encode#72-20 72744334 187.1 ns/op 144 B/op 2 allocs/op
BenchmarkBinaryPack/encode#1024-20 17048832 660.6 ns/op 1200 B/op 2 allocs/op
BenchmarkBinaryPack/encode#16384-20 2085050 6280 ns/op 18495 B/op 2 allocs/op
BenchmarkBinaryPack/encode_with_pool#72-20 34700313 109.2 ns/op 64 B/op 2 allocs/op
BenchmarkBinaryPack/encode_with_pool#1024-20 39370662 101.1 ns/op 64 B/op 2 allocs/op
BenchmarkBinaryPack/encode_with_pool#16384-20 18445262 177.2 ns/op 64 B/op 2 allocs/op
BenchmarkBinaryPack/encode_to#72-20 705428736 16.96 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/encode_to#1024-20 575312358 20.78 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/encode_to#16384-20 100000000 113.4 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode_meta#72-20 1000000000 2.887 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode_meta#1024-20 1000000000 2.882 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode_meta#16384-20 1000000000 2.876 ns/op 0 B/op 0 allocs/op
BenchmarkBinaryPack/decode#72-20 100000000 85.63 ns/op 80 B/op 1 allocs/op
BenchmarkBinaryPack/decode#1024-20 7252350 445.4 ns/op 1024 B/op 1 allocs/op
BenchmarkBinaryPack/decode#16384-20 554329 5499 ns/op 16384 B/op 1 allocs/op
BenchmarkBinaryPack/decode_with_pool#72-20 109352595 33.97 ns/op 16 B/op 1 allocs/op
BenchmarkBinaryPack/decode_with_pool#1024-20 85589674 36.27 ns/op 16 B/op 1 allocs/op
BenchmarkBinaryPack/decode_with_pool#16384-20 26163607 140.4 ns/op 16 B/op 1 allocs/op总结一下
通义千问的
Binary Pack:
- encode_to:性能最优,几乎没有内存分配,适用于高性能要求的场景。
- encode_with_pool:使用内存池优化,显著减少了时间和内存开销,适用于大多数场景。
- encode:标准方法,时间和内存开销较高。
MsgPack:
- encode_with_buf:使用预分配的缓冲区,显著减少了时间和内存开销,适用于大多数场景。
- encode:标准方法,时间和内存开销较高。
- decode:解码性能一般,内存开销较高。
Json Pack:
- encode_with_buf:使用预分配的缓冲区,显著减少了时间和内存开销,适用于大多数场景。
- encode:标准方法,时间和内存开销较高。
- decode:解码性能较差,内存开销较高。
Json Compress Pack:
- encode:标准方法,时间和内存开销非常高,不推荐用于高性能要求的场景。
- decode:解码性能较差,内存开销较高。
我总结的
在内网的环境进行传输,一般网络带宽不会成为瓶颈,所以可以不用考虑数据压缩,上面结果也看到压缩非常占用资源;如果对数据内容不关心且数据量非常多的情况下(比如传输 pcap 包),那么使用自定义协议可能更合适一些,固定长度的元数据解析起来优化空间巨大,二进制解析比 json/msgpack 快内存分配也非常少。
文章转载自:文一路挖坑侠
原文链接:https://www.cnblogs.com/shuqin/p/18427020
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构