深圳定制建设网站搜资源
一、抓包第一次请求
url = 'aHR0cDovL2N5eHcuY24vQ29sdW1uLmFzcHg/Y29saWQ9MTA='
抓包,需要清理浏览器cookie,或者无痕模式打开网址,否则返回的包不全,依照下图中的第一个包进行requests请求

第一次请求后返回
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/><meta http-equiv="Cache-Control" content="no-store, no-cache, must-revalidate, post-check=0, pre-check=0"/><meta http-equiv="Connection" content="Close"/><script type="text/javascript">function stringToHex(str){var val="";for(var i = 0; i < str.length; i++){if(val == "")val = str.charCodeAt(i).toString(16);else val += str.charCodeAt(i).toString(16);}return val;}function YunSuoAutoJump(){ var width =screen.width; var height=screen.height; var screendate = width + "," + height;var curlocation = window.location.href;if(-1 == curlocation.indexOf("security_verify_")){ document.cookie="srcurl=" + stringToHex(window.location.href) + ";path=/;";}self.location = "/Column.aspx?colid=10&security_verify_data=" + stringToHex(screendate);}</script><script>setTimeout("YunSuoAutoJump()", 50);</script></head><!--2023-10-11 11:55:23--></html>
其中stringToHex方法,用于将字符串转换为十六进制表示:
function stringToHex(str) {var val = "";for (var i = 0; i < str.length; i++) {if (val == "") val = str.charCodeAt(i).toString(16);else val += str.charCodeAt(i).toString(16);}return val;
}
用python实现
def stringToHex(data):valu = ''for i in range(0, len(data), 1):# 获取字符串中索引为 i 的字符的 Unicode 值,并转换为十六进制字符串表示unicode_value = ord(data[i])val = hex(unicode_value)[2:] # [2:] 是为了去掉十六进制字符串前面的 '0x' 前缀valu = valu + val # 顺序不能反,否则转换的十六进制是倒着的return valu
YunSuoAutoJump()方法,设置了cookies中的一个srcurl值,还有第二次请求的url:
function YunSuoAutoJump() {var width = screen.width;var height = screen.height;var screendate = width + "," + height;var curlocation = window.location.href;if (-1 == curlocation.indexOf("security_verify_")) {document.cookie = "srcurl=" + stringToHex(window.location.href) + ";path=/;";}self.location = "/Column.aspx?colid=10&security_verify_data=" + stringToHex(screendate);
}
screendate是定值,因此
url2 = url + '&security_verify_data=313232302c363836'
二、第二次请求
观察浏览器抓到的第二个请求的cookies:
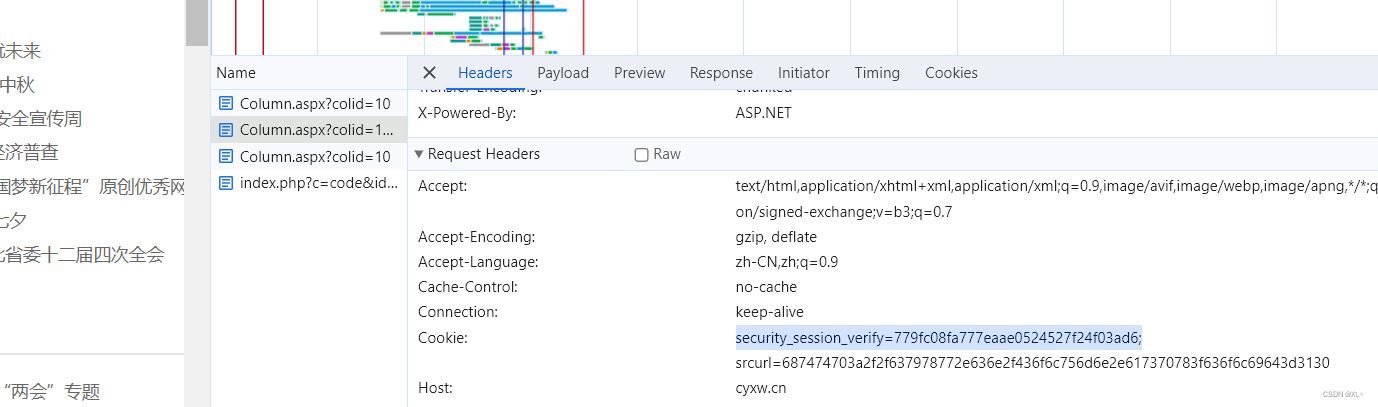
发现cookies中除srcurl还有security_verify_data,与第一次请求对比发现,在第一次请求时携带security_verify_data,如下图:
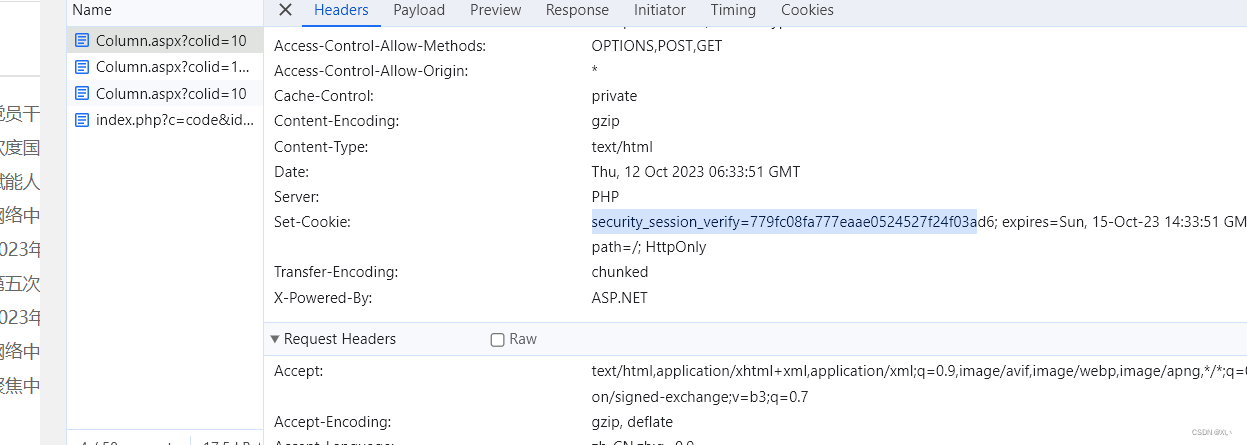
因此第二次请求的cookies为:
headers1 = resp1.headers.get('Set-Cookie')
result = headers1.split(';')[0]
cookies = {}
key, value = result.split('=')
cookies[key] = valuekey = 'srcurl'
value = stringToHex(url)
cookies[key] = value
进行第二次请求,返回
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/><meta http-equiv="Cache-Control" content="no-store, no-cache, must-revalidate, post-check=0, pre-check=0"/><meta http-equiv="Connection" content="Close"/>
<script>var cookie_custom = {hasItem: function(sKey) {return (new RegExp("(?:^|;\\s*)" + encodeURIComponent(sKey).replace(/[\-\.\+\*]/g, "\\$&") + "\\s*\\=")).test(document.cookie);},removeItem: function(sKey, sPath) {if (!sKey || !this.hasItem(sKey)) {return false;}document.cookie = encodeURIComponent(sKey) + "=; expires=Thu, 01 Jan 1970 00:00:00 GMT" + (sPath ? "; path=" + sPath : "");return true;}
};function YunSuoAutoJump() {self.location = "aHR0cDovL2N5eHcuY24vQ29sdW1uLmFzcHg/Y29saWQ9MTA=";}
</script>
<script>setTimeout("cookie_custom.removeItem('srcurl');YunSuoAutoJump();", 50);</script></head></html>由返回可知,第三次请求的url与第一次请求一致,cookies要除去第二次请求的srcurl这个键,再与浏览器中的第三次请求进行对比。
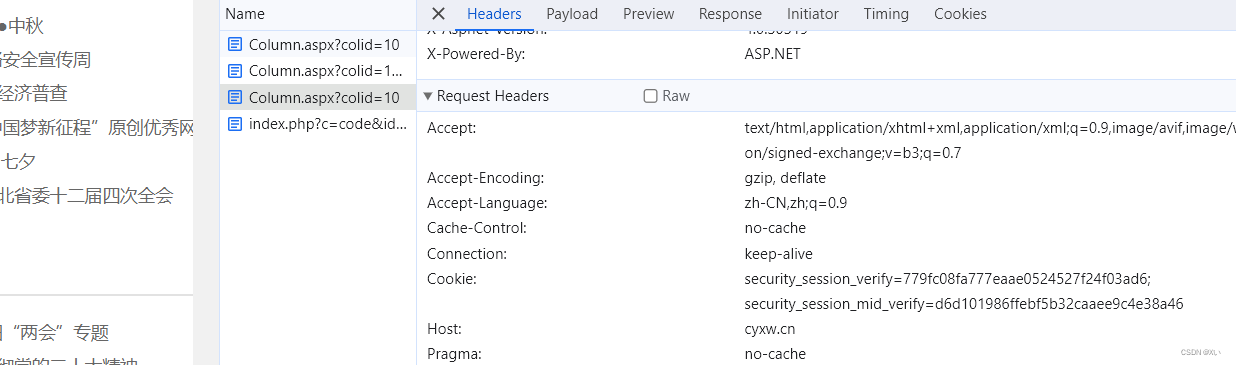
cookies中多了security_session_mid_verify这个键,同理可知,这个值在第二次请求的Set-Cookie处取得,cookies如下
headers2 = resp2.headers.get('Set-Cookie')
key, value = headers2.split(';')[0].split('=')
cookies[key] = value
cookies.pop('srcurl') # 删去srcurl键值对
三、第三次请求
resp3 = requests.get(url, headers=headers, verify=False, cookies=cookies).content
此网站如果使用requests.get().text返回的内容不对,所以用content查看返回内容,发现是乱码,部分如下:
\xe5\x9b\xbe\xe7\x89\x87\xe6\x87\x92\xe5\x8a\xa0\xe8\xbd\xbd\r
先解码,再删去返回中的\r,即返回正文内容
text = resp3.decode().replace('\r', '')