网站建设目的分析建立网站有哪些步骤
目录
一、什么是正则表达式?
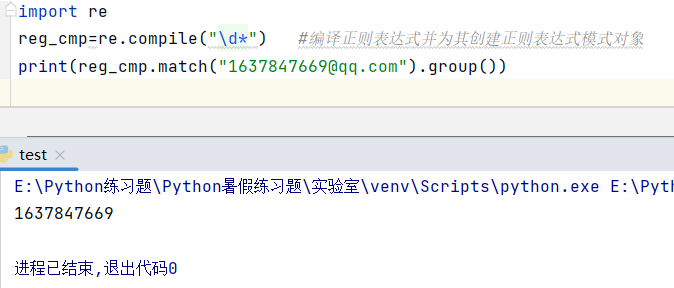
二、re.compile()编译函数
三、group()获取匹配结果函数
四、常用匹配规则
4.1匹配单个字符
4.2匹配前字符次数
4.3匹配原生字符串
4.4匹配字符串开头和结尾
4.5分组匹配
五、re.match()开头匹配函数
六、re.search()全文搜索函数
七、re.findall()查找所有函数
八、re.sub()与re.subn()查找替换函数
九、re.split()分割字符串函数
十、贪婪模式和非贪婪模式
一、什么是正则表达式?
所谓的正则表达式其实就是一些特殊字符规则组合。通过这些字符规则组合开发者可以检索并替换出一些符合这种规则的字符串文本数据。
二、re.compile()编译函数
可以将包含有正则表达式的字符串编译成字节码。
优点:之前每次调用re.match( )函数匹配字符串时,python解释器就会为其频繁的申请和释放空间,用来保存其正则表达式字符串。而通过调用re.complie( )函数,解释器只需为包含有正则表达式的字符串申请一次内存空间就可以了,以后每使用此正则表达式匹配字符串时就可以直接拿来用,而无需重复频繁为其申请内存空间,从而在很大程度上提高运行效率。
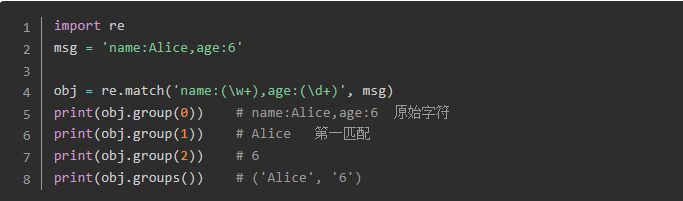
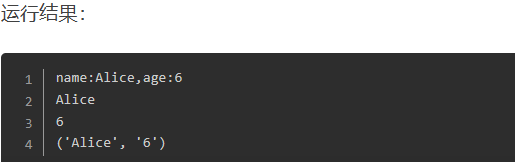
三、group()获取匹配结果函数
groups( )方法的返回值是一个元组,元组中包含正则表达式内所有捕获组()检索到的字符串。
group()方法用来获取正则表达式检索到的字符串。一般在re.match( )的正则表达式实参中一个小括号就是一个捕获组。
用法:group( 捕获组0[,捕获组1][,捕获组2][......] )
0: 表示获取正则表达式检索到的源字符串结果,这也是默认值。
1: 表示获取正则表达式中第一个()检索到的字符串
2: 表示获取正则表达式中第二个()检索到的字符串
以此类推........
四、常用匹配规则
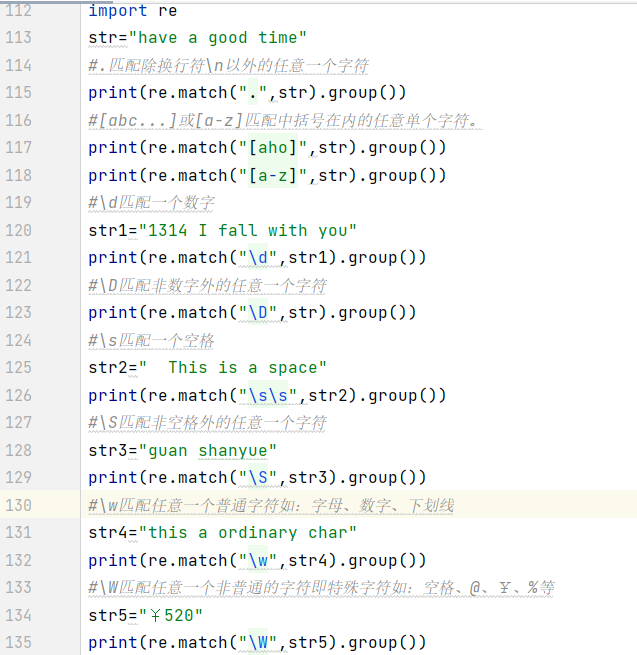
4.1匹配单个字符
.(点):匹配任意一个字符,除了换行符'\n'。
[abc...]:匹配一个字符,此字符可以是a、b或c。也可以写成范围[a-z]。
\d:匹配一个数字,即0~9。
\D:匹配除数字外的任意一个字符。
\s:匹配一个空格,一个tab键相当于2个空格。
\S:匹配除空格或tab键之外的任意一个字符。
\w:匹配一个普通字符,即a-z、A-Z、0-9、_
\W:匹配一个非普通字符即特殊字符,如:空格、@、$等
运行结果:

4.2匹配前字符次数
* :前一个字符可以匹配0次、1次或多次即任意次。直到不满足匹配规则返回之前匹配到的字符串。
+ :前一个字符必须至少匹配1次,否则匹配失败。
?:前一个字符最多匹配1次或者不匹配返回空字符。
{m} :前一个字符必须精确匹配m次。
{m,} :前一个字符至少匹配m次,直到不满足匹配规则结束。
{mix,max} :前一个字符必须匹配min~max次 即最少匹配min次,最多匹配max次;且不能为负数。
注意:以上字符需要与前一个字符配合使用即作用于前字符。

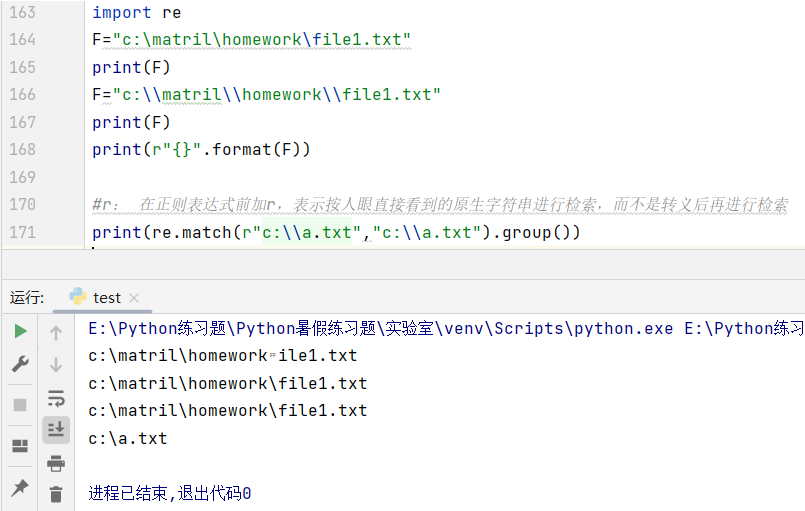
4.3匹配原生字符串
在许多编程语言中"\"往往表示转义字符,如:\n表示换行、\t表示tab键;为了表示"\"本身需要再加一个\ ,形成”\\“格式。或者在字符串的前面加“r"字符:表示按肉眼看到的字符串原意检索。
4.4匹配字符串开头和结尾
^str :表示字符串开头,即匹配以str开头的字符串
[^a] :此时“^”表示取反,即匹配除字母a的任意一个字符
str$ :表示字符串结尾,即匹配字符串的结尾即检索的目标字符串必须以str结尾

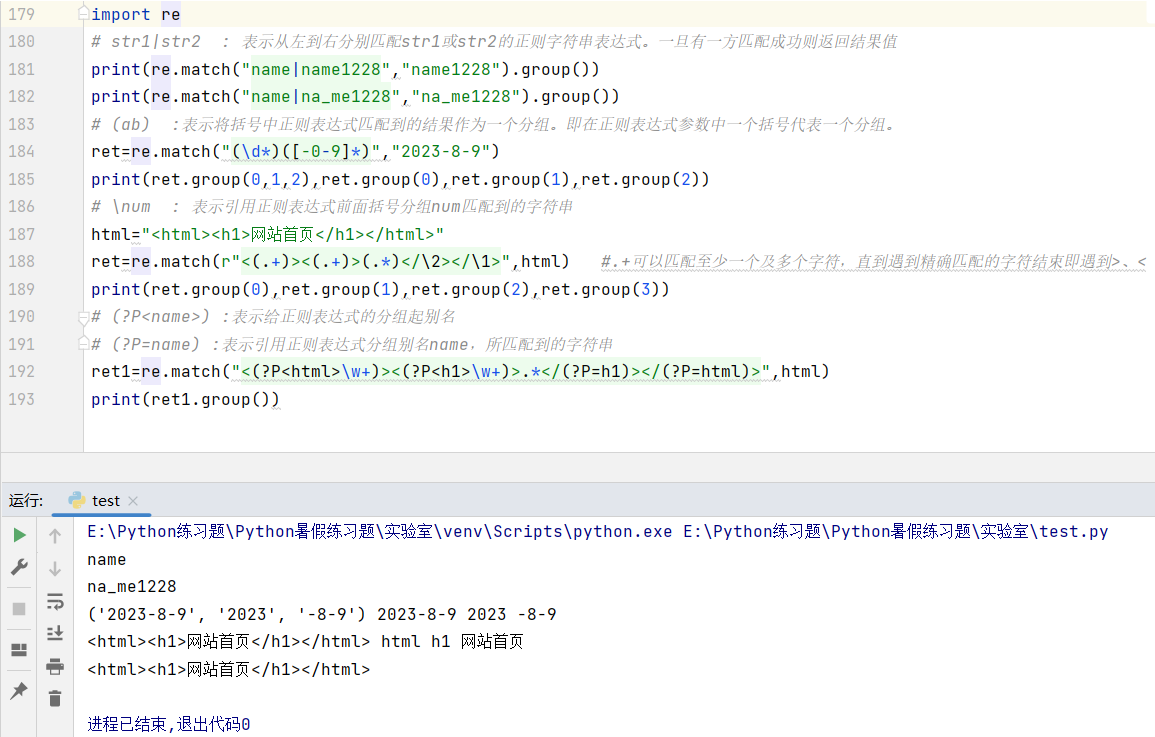
4.5分组匹配
str1|str2 : 表示从左到右分别匹配str1或str2的正则字符串表达式。一旦有一方匹配成功则返回结果值。
(ab) :表示将括号中正则表达式匹配到的结果作为一个分组。即在正则表达式参数中一个括号代表一个分组。
\num : 表示引用正则表达式前面括号分组num匹配到的字符串。
(?P<name>) :表示给正则表达式的分组起别名。
(?P=name) :表示引用前面正则表达式分组别名name所匹配到的字符串。
五、re.match()开头匹配函数
re.match()函数只能匹配字符串的开头。如果要匹配的正则表达式字符串不在原字符串的开头则匹配不成功返回值None;匹配成功返回re.match类对象。
用法:re.match(pattern,string,flags)
pattern: 要匹配的正则表达式
string: 要检索的源字符串文本
flags: 标志位,用来控制正则表达式的匹配方式,如: re.I表示忽略大小写,re.M表示多行匹配,re.S使正则表达式中“.”的匹配包括换行符\n在内任意一个字符等等。


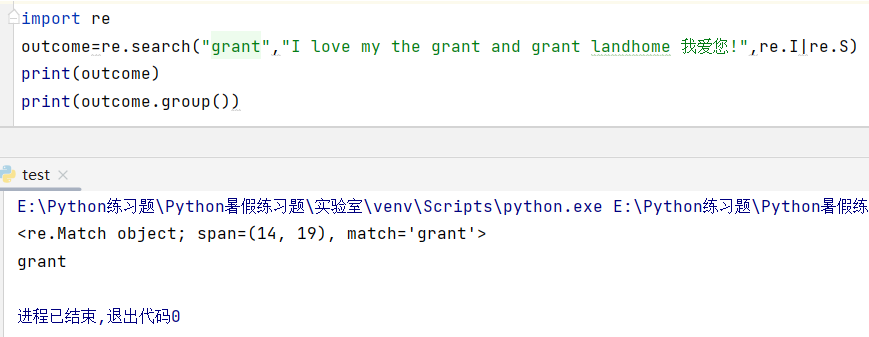
六、re.search()全文搜索函数
从全文中从前往后搜索指定字符串,一旦找到则立即返回搜索到的对象。
用法:re.search(pattern,dest, flags)
pattern: 正则表达式字符串
dest: 要对其搜索的文本字符串
flags: 标志位。re.I忽略大小写,re.M多行匹配
说明:span=(14,19)表示匹配到的字符串在源文本中的下标位置,不包含19。
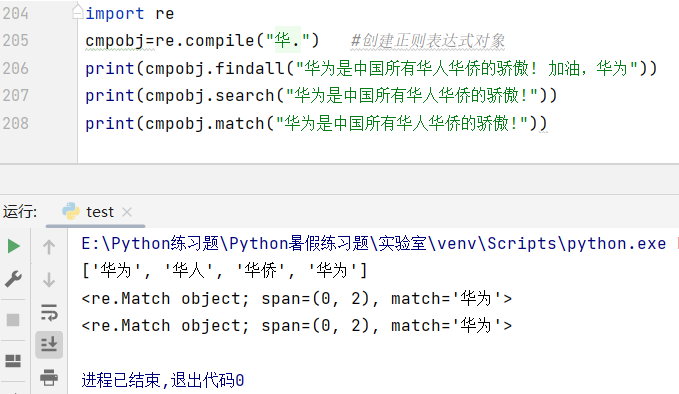
七、re.findall()查找所有函数
用法:re.findall(pattern,dest_str,flags)
pattern: 正则表达式字符串
dest_str: 要对其搜索的文本字符串
flags: 控制正则表达式匹配方式。re.I忽略大小写,re.M多行匹配
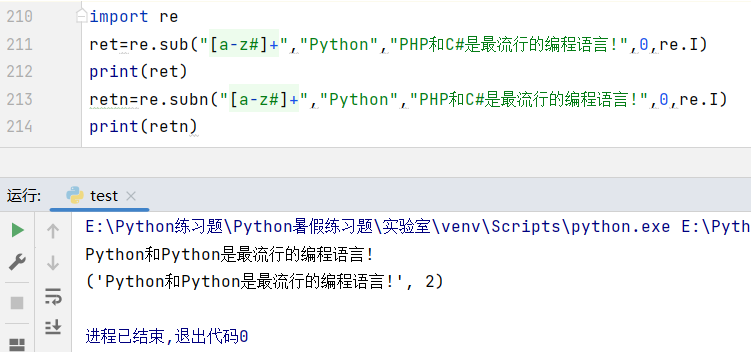
八、re.sub()与re.subn()查找替换函数
re.sub( )函数: 将文本字符串中正则表达式查找到的字符串替换为指定的字符串后并返回。
用法:re.sub(pattern,sub,dest_str,counts=0,flags)
pattern: 匹配模式即正则表达式
sub: 替换为的字符串
dest_str: 要替换的文本字符串
counts: 替换的最大次数,默认为0表示替换全部
flags:控制正则表达式匹配方式
说明: re.subn( )函数与re.sub( )函数的功能一样。只不过在以元组的形式返回替换后的文本字符串时,还会包含原文被替换的字符串个数。
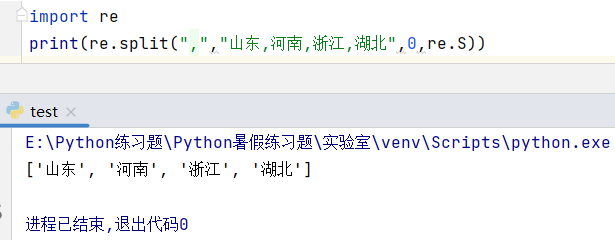
九、re.split()分割字符串函数
以文本字符串中的某个字符作为分割符,实现对文本字符串的分割并以列表的形式返回分割后的文本字符串。
用法:re.split(pattern, dest_str, max_split, flags)
pattern: 分割符
dest_str: 要分割的文本字符串
max_split: 最大分割数。默认为0表示无限制
flags: 设置正则表达式匹配的方式。
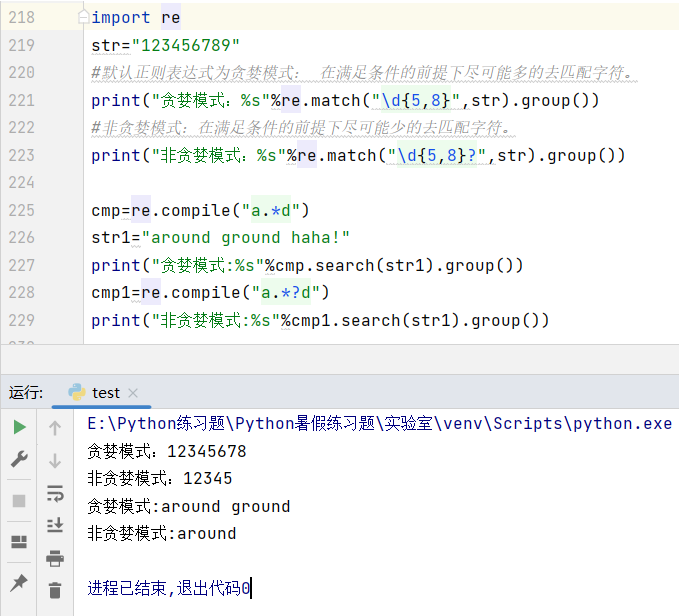
十、贪婪模式和非贪婪模式
贪婪模式:在满足正则规则的情况下尽可能多的匹配字符
非贪婪模式: 在满足正则规则的情况下尽可能少的匹配字符
在python正则表达式的数量匹配字符中默认是贪婪模式,如果想将正则表达式的匹配变为非贪婪模式只需在数量匹配字符的后面加上?如:"*",“+”,“?”,{min,max}
@声明:“山月润无声”博主知识水平有限,以上文章如有不妥之处,欢迎广大IT爱好者指正,小弟定当虚心受教!