个人业务网站创建网站优化外包多少钱
数据处理
Normalize 归一化 & regularzation正则化
在看代码时候,经常会看到normalize的部分,之前一直不太关注,因为不是所有论文代码都有这部分处理,之前自己没仔细看,现在想想 应该是再 utils里面 的 normalize 对 特征矩阵进行 了归一化(行或者列)。
有关正则化的一个博文

1. 正则化 通过对参数施加,避免过拟合
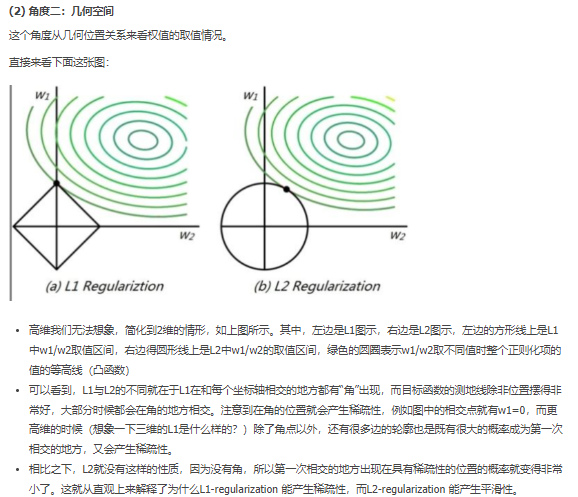
L0范数 稀疏 Lasso回归 L0会使解位于坐标轴上,解的坐标维度会有0,产生稀疏的效果,从而 部分维度=0,部分=1,间接产生 特征选择 的效果
比较详细,从p范数出发,解释了0范数是稀疏,但因为求解L0范数 是NP-hard的,理论表面L1范数是L0的最好逼近。因此常用L1范数进行求解,L2范数是稠密范数,常对参数w进行正则化。

L2范数 岭回归 权重衰减。

L1,L2 范数 到底为什么能避免过拟合? 链接中还包含 病态矩阵(对矩阵微小扰动,会使得解变化很大,原因:列向量相关性太强 病态矩阵)
数学角度

几何角度
更加详细的数学推导!!!! 推荐~~~:
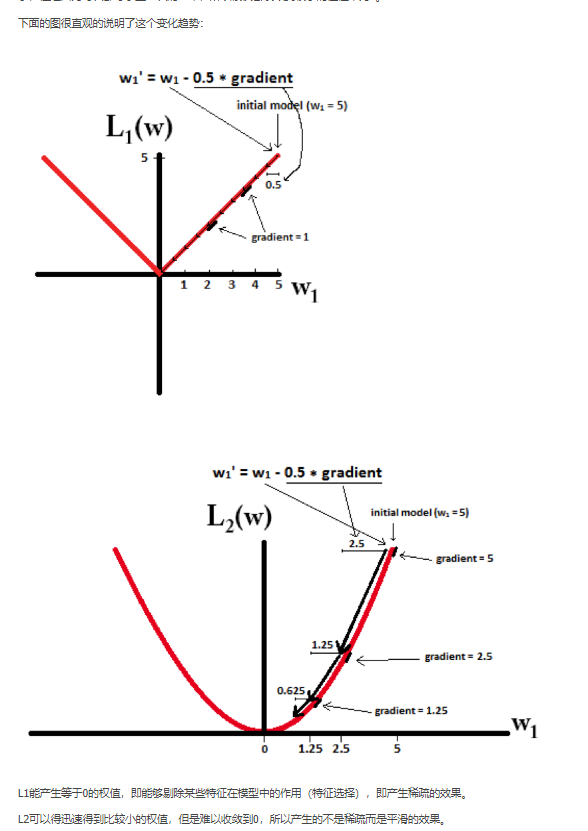
数学损失函数 梯度、特征值 角度来说明L2范数
结论是 L2范数能够 对 重要参数抑制小,对不重要的参数抑制大,使得不重要的参数 对model 起的作用小,从而使得model 对不同参数不同对待,不用都去考虑,不用过于 拟合 数据。从而减轻过拟合。
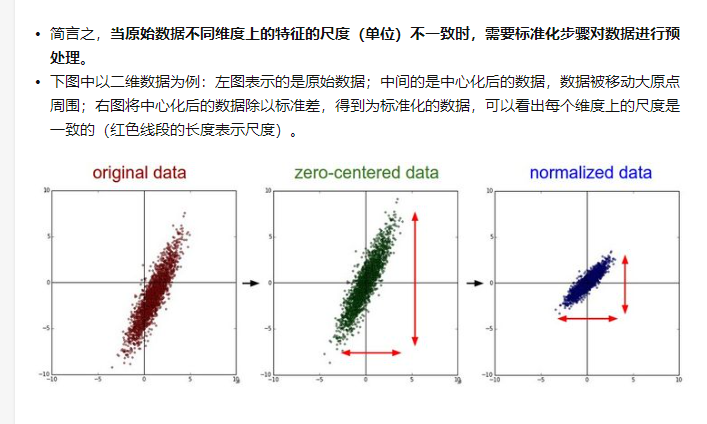
2. 归一化和标准化
归一化 和标准化 都能对数据进行缩放。
标准化 又称为 Z-score 去中心归一化。 通过计算 整体数据的 均值和方差 进行求解。
归一化通过 利用数据 的最大值和最小值 对数据进行缩放,常用于已知最大最小值。

为什么要做 中心化和标准化
sklearn.preprocessing.normalize/ Normalizer() and .scale/ StandardScaler()
具体见
直接采用两个两个函数,可以对数据进行标准化处理,normalize是 正则化 计算,采用l1,l2。 scale 是标准化,即均值方差z-score
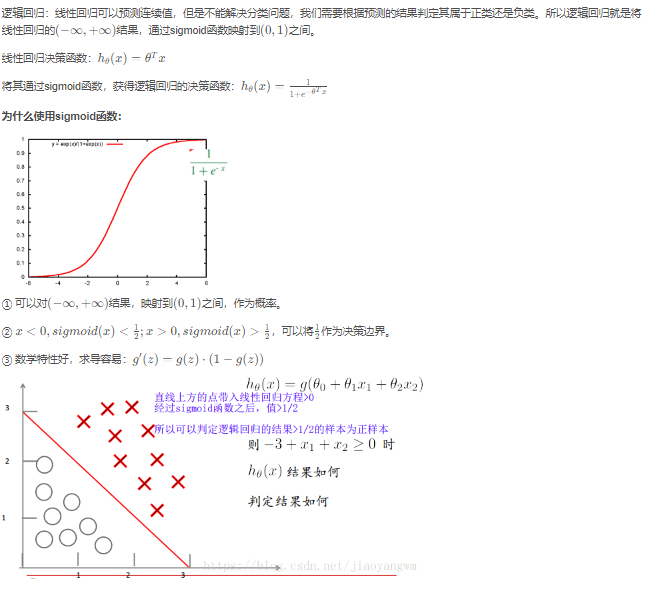
3. 线性回归& 逻辑回归 LR
线性回归解决预测问题,逻辑回归通过sigmoid函数 将(-∞,∞)的值映射到(0,1)。从而解决分类问题