北京出大大事了seo工具包
「作者主页」:士别三日wyx
「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者
「推荐专栏」:对网络安全感兴趣的小伙伴可以关注专栏《网络安全入门到精通》
sklearn数据集
- 二、安装sklearn
- 二、获取数据集
- 三、数据集划分
机器学习是人工智能的一个实现途径,可以从「数据」中自动分析获得「模型」,并利用模型对未知数据进行「预测」。
简单来说就是从历史数据中总结规律,用来解决新出现的问题。
从数据中总结规律,需要提供一个「数据集」,数据集由「特征值」和「目标值」两部分组成。
机器学习有很多好用的工具,这里我们使用sekearn。
sklearn是基于Python的机器学习工具包,自带大量数据集,可供我们练习各种机器学习算法。
二、安装sklearn
环境要求:
- Python(>=2.7 or >=3.3)
- NumPy (>= 1.8.2)
- SciPy (>= 0.13.3)
先安装 numpy、scipy,再安装 scikit-learn
PyCharm左上角【file】-【Settings】-【Project:pythonProject】-【Python Interpreter】
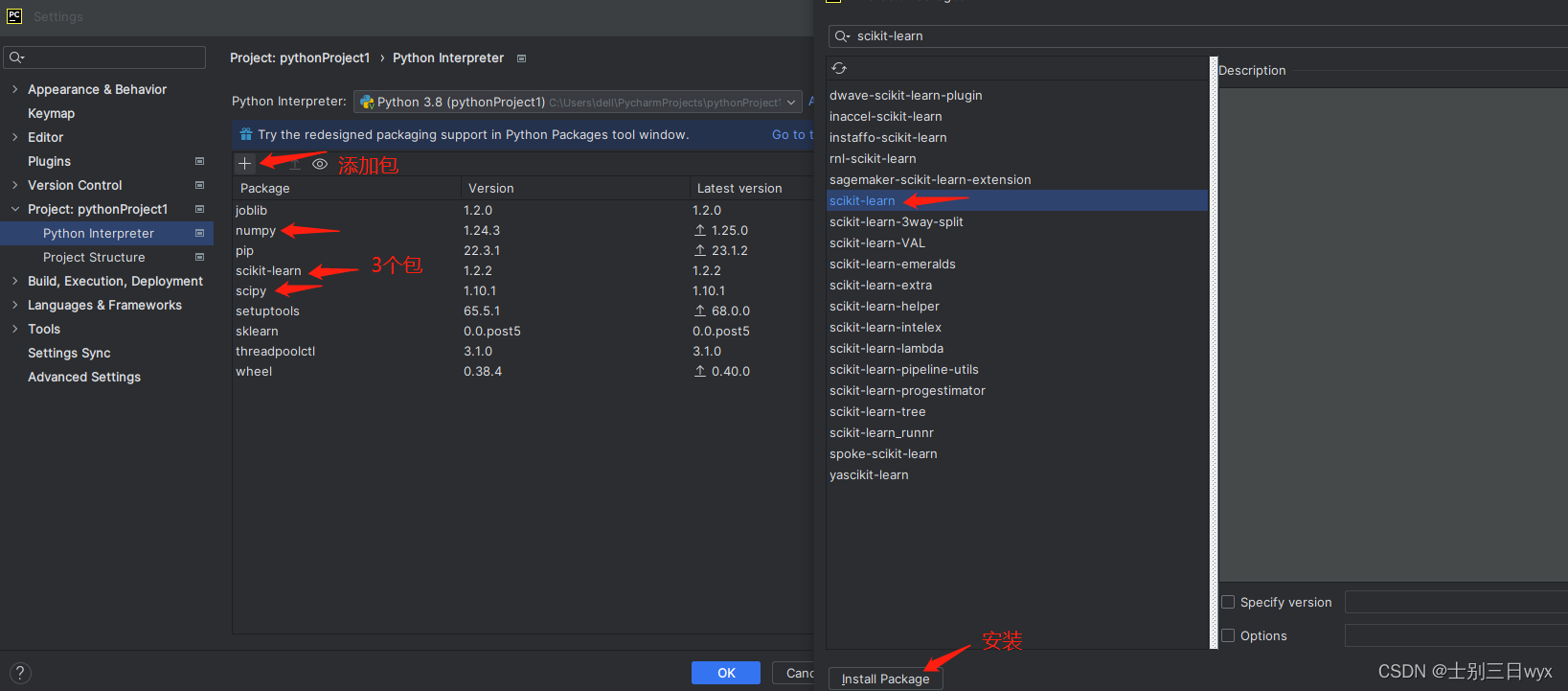
二、获取数据集
sklearn数据集有有三种「获取数据」的方式:
- sklearn.datasets.load_*():小规模数据集(本地加载)
- sklearn.datasets.fetch_*():大规模数据集(在线下载)
- sklearn.datasets.make_*():本地生成数据集(本地构造)
sklearn数据集的「返回值」是字典格式:
- data:特征值数据数组
- target:目标值数据数组(标签)
- target_names:标签名(目标值和标签的对应关系)
- DESCR:数据描述
- feature_names:特征名
接下来,我们获取一个自带的本地数据集:
from sklearn import datasets# 获取数据集
iris = datasets.load_iris()
# 打印数据集
print(iris)
输出:
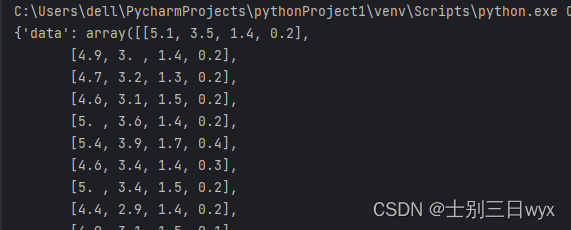
从输出结果来看,它返回的数据集是一个字典,里面包含了特征值(data)、目标值(target)等信息。
我们可以调用返回值「属性」,单独查看数据集的某个信息:
from sklearn import datasets# 获取数据集
iris = datasets.load_iris()# 查看数据值
print(iris.data)
# 查看目标值(标签)
print(iris.target)
# 查看标签名
print(iris.target_names)
# 查看数据描述
print(iris.DESCR)
# 查看特征名
print(iris.feature_names)
三、数据集划分
数据集通常会划分为两个部分:
- 「训练数据」:用于训练,生成模型。
- 「测试数据」:用于检验,判断模型是否有效。
sklearn.model_selection.train_test_split() 用来划分数据集
参数:
- x:(必选)数组类型,数据集的特征值
- y:(必选)数组类型,数据集的目标值
- test_size:(可选,默认0.25)浮点型,测试集的大小
- random_state:(可选)整型,随机数种子,不同的随机数对应不同的采样结果。
返回值:
- 训练集特征值、测试集特征值、训练集目标值、测试集目标值
接下来,我们对刚才获取的本地数据集进行划分,测试集大小不给值,就是默认的0.25,意思是25%当做测试数据、剩下的75%当做训练数据。
from sklearn import datasets
from sklearn import model_selection# 获取数据集
iris = datasets.load_iris()# 数据集的特征值
data_arr = iris.data
# 数据集的目标值(标签)
target_arr = iris.targetx_data, y_data, x_target, y_target = model_selection.train_test_split(data_arr, target_arr)
print('训练集特征值', x_data)
print('测试集特征值', y_data)
print('训练集目标值', x_target)
print('测试集目标值', y_target)