鑫三科技网站设计粤语seo是什么意思
LangChain学习文档
- 【LangChain】向量存储(Vector stores)
- 【LangChain】向量存储之FAISS
概要
存储和搜索非结构化数据的最常见方法之一是嵌入它并存储生成的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。向量存储负责存储嵌入数据并为您执行向量搜索。
内容
本篇讲述与 VectorStore 相关的基本功能。使用向量存储的一个关键部分是创建要放入其中的向量,这通常是通过嵌入创建的。因此,建议您在深入研究之前熟悉文本嵌入模型接口。
有许多很棒的向量存储选项,以下是一些免费、开源且完全在本地计算机上运行的选项。查看许多出色的托管产品的所有集成。
文本嵌入模型接口
我们想要使用 OpenAIEmbeddings,因此我们必须获取 OpenAI API 密钥。
import os
import getpassos.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')下面展示三个嵌入文本模型接口。
Chroma
本篇讲述使用Chroma向量数据库,该数据库作为一个库在本地计算机上运行。
pip install chromadb
我们想要使用 OpenAIEmbeddings,因此我们必须获取 OpenAI API 密钥。
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma# 加载文档,将其分割成块,嵌入每个块并将其加载到向量存储中。
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
# 注意这里
db = Chroma.from_documents(documents, OpenAIEmbeddings())
FAISS
本演练使用 FAISS 矢量数据库,该数据库利用 Facebook AI 相似性搜索 (FAISS) 库。
pip install faiss-cpu
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS# 加载文档,将其分割成块,嵌入每个块并将其加载到向量存储中。
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
Lance
本笔记本展示了如何使用与基于 Lance 数据格式的 LanceDB 矢量数据库相关的功能。
pip install lancedb
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import LanceDBimport lancedb
# 基于 Lance 数据格式
db = lancedb.connect("/tmp/lancedb")
table = db.create_table("my_table",data=[{"vector": embeddings.embed_query("Hello World"),"text": "Hello World","id": "1",}],mode="overwrite",
)# 加载文档,将其分割成块,嵌入每个块并将其加载到向量存储中。
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
# 创建嵌入的向量存储
db = LanceDB.from_documents(documents, OpenAIEmbeddings(), connection=table)
相似性搜索
query = "总统对科坦吉·布朗·杰克逊说了些什么"
docs = db.similarity_search(query)
print(docs[0].page_content)
结果:
今晚。我呼吁参议院: 通过《投票自由法案》。通过约翰·刘易斯投票权法案。当你这样做的时候,通过《披露法案》,这样美国人就可以知道谁在资助我们的选举。今晚,我要向一位毕生为这个国家服务的人表示敬意:斯蒂芬·布雷耶法官——退伍军人、宪法学者、即将退休的美国最高法院法官。布雷耶法官,感谢您的服务。总统最重要的宪法责任之一是提名某人在美国最高法院任职。四天前,当我提名巡回上诉法院法官科坦吉·布朗·杰克逊时,我就这样做了。我们国家最顶尖的法律头脑之一,他将继承布雷耶大法官的卓越遗产。
通过向量进行相似性搜索(Similarity search by vector)
还可以使用similarity_search_by_vector 与给定嵌入向量相似的文档进行搜索,该向量接受嵌入向量作为参数而不是字符串。
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content)
查询相同,所以结果也相同。
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
异步操作(Asynchronous operations)
向量存储通常作为需要一些 IO 操作的服务,一般是单独运行的,因此它们可能会被异步调用。这会带来性能优势,因为您不必浪费时间等待外部服务的响应。如果您使用异步框架(例如 FastAPI),这一点也可能很重要。
Langchain 支持向量存储上的异步操作。所有方法都可以使用其异步对应方法进行调用,前缀 a 表示异步。
Qdrant 是一个向量存储,它支持所有异步操作,因此将在本节中使用它。
# 单独执行安装
pip install qdrant-client
# 引入模块
from langchain.vectorstores import Qdrant
异步创建向量存储(Create a vector store asynchronously)
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")(相似性搜索)Similarity search
query = "总统对科坦吉·布朗·杰克逊说了些什么"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
结果:
今晚。我呼吁参议院: 通过《投票自由法案》。通过约翰·刘易斯投票权法案。当你这样做的时候,通过《披露法案》,这样美国人就可以知道谁在资助我们的选举。
今晚,我要向一位毕生为这个国家服务的人表示敬意:斯蒂芬·布雷耶法官——退伍军人、宪法学者、即将退休的美国最高法院法官。布雷耶法官,感谢您的服务。
总统最重要的宪法责任之一是提名某人在美国最高法院任职。
四天前,当我提名巡回上诉法院法官科坦吉·布朗·杰克逊时,我就这样做了。我们国家最顶尖的法律头脑之一,他将继承布雷耶大法官的卓越遗产。
通过向量进行相似性搜索(Similarity search by vector)
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
最大边际相关性搜索 (MMR)(最大边际相关性搜索 (MMR))
最大边际相关性优化了所选文档之间查询的相似性和多样性。异步 API 也支持它。
query = "总统对科坦吉·布朗·杰克逊说了些什么"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):print(f"{i + 1}.", doc.page_content, "\n")
结果:
1. 今晚。我呼吁参议院: 通过《投票自由法案》。通过约翰·刘易斯投票权法案。当你这样做的时候,通过《披露法案》,这样美国人就可以知道谁在资助我们的选举。
今晚,我要向一位毕生为这个国家服务的人表示敬意:斯蒂芬·布雷耶法官——退伍军人、宪法学者、即将退休的美国最高法院法官。布雷耶法官,感谢您的服务。
总统最重要的宪法责任之一是提名某人在美国最高法院任职。
四天前,当我提名巡回上诉法院法官科坦吉·布朗·杰克逊时,我就这样做了。我们国家最顶尖的法律头脑之一,他将继承布雷耶大法官的卓越遗产。
2.我们无法改变我们之间的分歧。但我们可以改变我们前进的方式——在 COVID-19 和我们必须共同面对的其他问题上。
最近,在威尔伯特·莫拉警官和他的搭档杰森·里维拉警官的葬礼几天后,我访问了纽约市警察局。
他们当时正在接听 9-1-1 的电话,一名男子用偷来的枪开枪打死了他们。
莫拉警官当时 27 岁。
里维拉警官当时22岁。
这两位多米尼加裔美国人都在同一条街道上长大,后来他们选择担任警察巡逻。
我与他们的家人交谈,告诉他们,我们永远欠他们的牺牲,我们将继续履行他们的使命,恢复每个社区应有的信任和安全。
我已经研究这些问题很长时间了。
我知道什么是有效的:投资于预防犯罪和社区警察,他们会遵守规则,了解社区,并且能够恢复信任和安全。
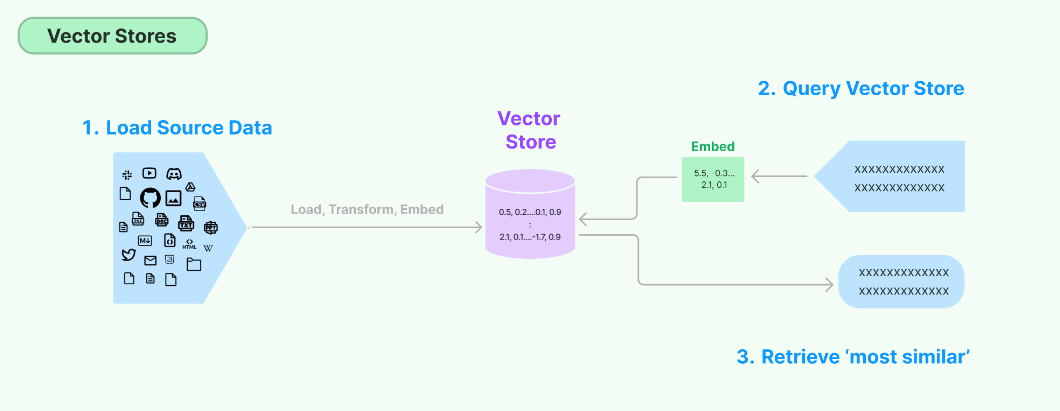
总结
本篇主要讲述的内容,其实都在这幅图里:
- 加载数据
- 通过embed,转成向量存储
- 查询条件进行embed
- 在3的基础上,再进行向量存储库的搜索
参考地址:
https://python.langchain.com/docs/modules/data_connection/vectorstores/