招商网网站建设方案今天最新新闻报道
文章目录
- 动机
- 方法
- 写作方面参考
Paper: https://arxiv.org/pdf/2111.06377.pdf
动机
首先简要介绍下BERT,NLP领域的BERT是基于Transformer架构,并采取无监督预训练的方式去训练模型。它提出的预训练方法在本质上是一种masked autoencoding,也就是MLM(masked language modeling):去除数据的一部分然后学习恢复。
自从ViT火了之后,Transformer架构也可以应用于CV领域中了,一些研究者就开始尝试研究ViT的无监督学习,比如Mocov3用对比学习的方法无监督训练ViT,此外也有一些研究开始借鉴BERT中的MLM方法,比如BEiT提出了用于图像的无监督学习方法: MIM(masked image modeling)。但尽管如此,NLP领域已经在BERT的这种masked autoencoding方法下取得了巨大的进展,而CV领域中在无监督预训练这一块远远落后,主流的无监督训练还是对比学习。其中这种masked autoencoding方法并不是没在图像领域应用过,很早便就出现了,比如Denoising Autoencoders。但是至今却未取得像在NLP领域中的巨大发展。MAE论文对这个问题做了以下分析(参考:视觉无监督学习新范式:MAE):
- 图像的主流模型是CNN,而NLP的主流模型是transformer,CNN和transformer的架构不同导致NLP的BERT很难直接迁移到CV。但是vision transformer的出现已经解决这个问题;
- 图像和文本的信息密度不同,文本是高语义的人工创造的符号,而图像是一种自然信号,两者采用masked autoencoding建模任务难度就不一样,从句子中预测丢失的词本身就是一种复杂的语言理解任务,但是图像存在很大的信息冗余,一个丢失的图像块很容易利用周边的图像区域进行恢复。也就是说:丢失一个单词去恢复句子很难,用MLM这样的方式去学习这样一个难的任务可以学到一些有意义的信息;但是丢失一个patch去恢复图像却很简单,这只用线性插值就可以实现了,用MIM这样的方式去学习这么简单的任务,几乎学不到什么有价值的信息。
- 用于重建的decoder在图像和文本任务发挥的角色有区别,从句子中预测单词属于高语义任务,encoder和decoder的gap小,所以BERT的decoder部分微不足道(只需要一个MLP),而对图像重建像素属于低语义任务(相比图像分类),decoder需要发挥更大作用:将高语义的中间表征恢复成低语义的像素值。
因此,本文提出了一种简单有效的用于ViT无监督预训练的方法,称为MAE(masked autoencoder)。MAE也属于MIM的范畴,可以将MAE看作是BERT的CV版本:

方法
MAE方法很简单,整体架构如下。针对以上的分析,MAE采用了MIM的思想,随机mask掉部分patchs然后进行重建,并有两个核心的设计: 1)设计了一个非对称的encoder-decoder结构,这个非对称体现在两方面:一方面decoder采用比encoder更轻量级设计,encoder首先使用linear将patch映射为embedding,然后采用的是ViT模型,decoder是一个包含几个transformer blocks轻量级模块,最后一层是一个linear层采用的是一个;另外一方面encoder只处理visible patchs,而decoder处理所有的patchs(插入masked patchs)。2)MAE采用很高的masking ratio(比如75%甚至更高),这样构建的学习任务大大降低了信息冗余,或者说增加了学习难度,使得encoder能学习到更高级的特征。此外,由于encoder只处理visible patchs,所以很高的masking ratio可以大大降低计算量。

MAE采用随机mask策略,对于mask ratio的选择如下:

其中的linear probing和Fine tune的区别是:linear probing把encoder冻结只加一个linear分类器训练,Fine tune是不冻结encoder完全放开训练。注意,decoder部分只是辅助无监督预训练的,具体到下游任务时就不需要它了。
不同mask ratio的效果:

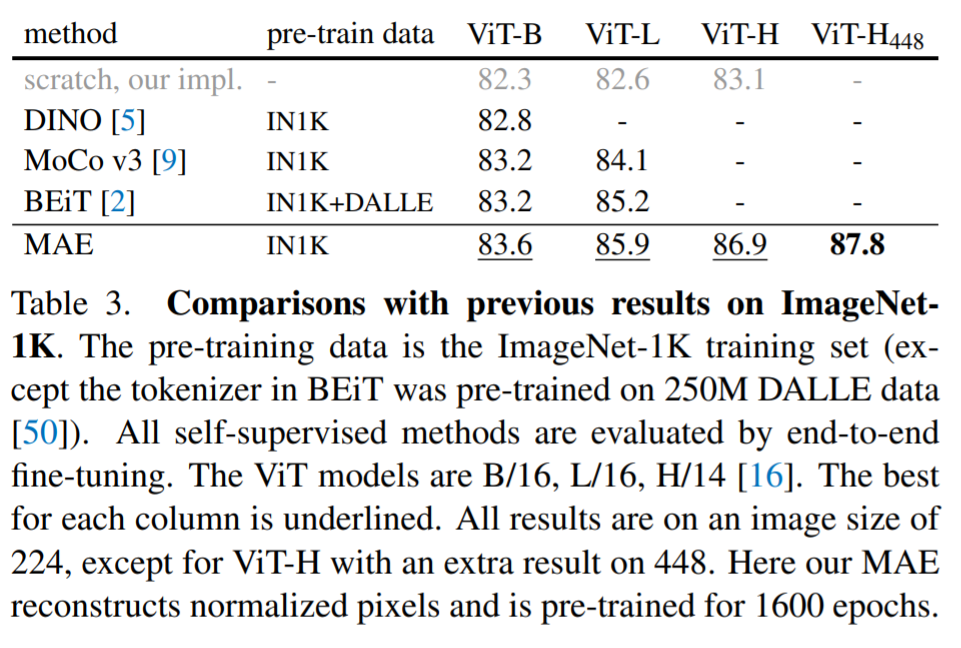
在ImageNet-1K上与其他自监督方法对比:
最后的loss只计算masked patchs。
写作方面参考
论文名《Masked Autoencoders Are Scalable Vision Learners》也是一个常用的强有力的句式:xxx are xxx。并且这样的表达会给人一种很客观,站在读者角度上的感觉。
当你做的模型比较大时,用scalable;当你做的模型比较快时,用efficient。
画图的一些细节: MAE的计算量主要出现在encoder部分,所以作者将encoder部分画的比decoder部分大。论文图中的每一个小细节,体现的都是文章的思想。