教育行业网站怎么做百度推广一个月费用
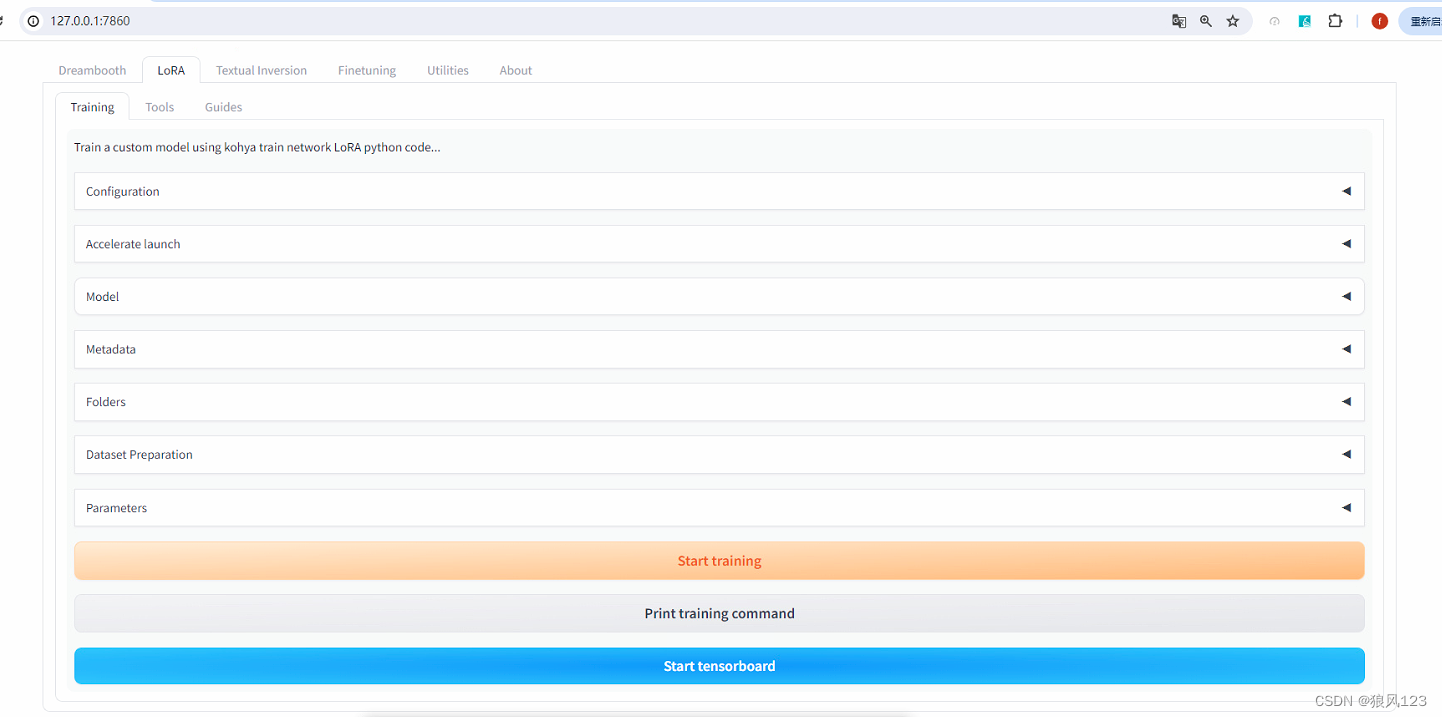
一. 使用kohya_ss的GUI版本(https://github.com/bmaltais/kohya_ss.git)
这个版本跟stable-diffusion-webui的界面很像,只不过是训练模型专用而已,打开的端口同样是7860。
1.双击setup.bat,选择1安装好xformers,pytorch等和cuda相关的库,然后可以control+C退出.将requirements.txt里面的内容除了“-e .”外复制到req.txt,然后在虚拟环境下({venv}\Scripts=E:\SD_WIN\kohya_ss\venv\Scripts)执行下面代码加速安装:
pip install -r {xxx}/req.txt -i https://pypi.tuna.tsinghua.edu.cn/simple安装结束后,重新双击setup.bat并选择1,查缺补漏。
2.双击gui.bat运行,这个和stable-diffusion-webui不一样,不会自动打开浏览器的。自行在chrome上输入“http://127.0.0.1:7860/”.


19:07:38-166454 INFO Start training LoRA Standard ...
19:07:38-167453 INFO Validating lr scheduler arguments...
19:07:38-168449 INFO Validating optimizer arguments...
19:07:38-169446 INFO Validating E:/SD_WIN/kohya_ss/logs existence and writability... SUCCESS
19:07:38-171441 INFO Validating E:/SD_WIN/kohya_ss/outputs existence and writability... SUCCESS
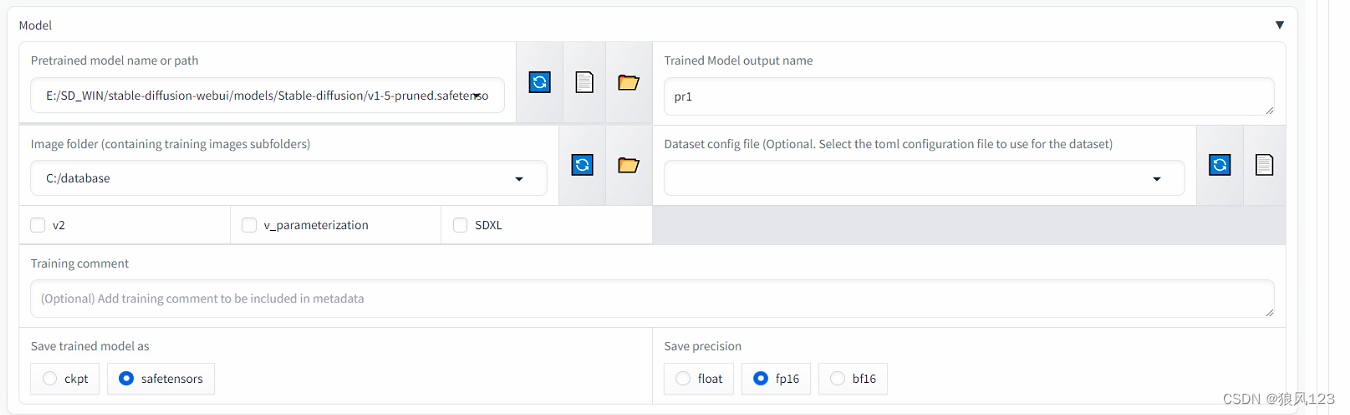
19:07:38-172439 INFO Validating E:/SD_WIN/stable-diffusion-webui/models/Stable-diffusion/sd_xl_base_1.0.safetensorsexistence... SUCCESS
19:07:38-173436 INFO Validating C:/sdxl existence... SUCCESS
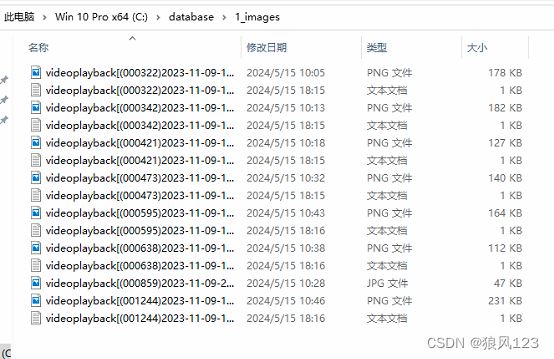
19:07:38-174433 INFO Folder 1_images: 1 repeats found
19:07:38-186400 INFO Folder 1_images: 8 images found
19:07:38-187399 INFO Folder 1_images: 8 * 1 = 8 steps
19:07:38-188396 INFO Regulatization factor: 1
19:07:38-189394 INFO Total steps: 8
19:07:38-190389 INFO Train batch size: 1
19:07:38-191387 INFO Gradient accumulation steps: 1
19:07:38-192384 INFO Epoch: 1
19:07:38-193383 INFO Max train steps: 1600
19:07:38-193383 INFO stop_text_encoder_training = 0
19:07:38-194380 INFO lr_warmup_steps = 160
19:07:38-221307 INFO Saving training config to E:/SD_WIN/kohya_ss/outputs\pr1_sdxl_20240515-190738.json...
19:07:38-256213 INFO Executing command: E:\SD_WIN\kohya_ss\venv\Scripts\accelerate.EXE launch --dynamo_backend no--dynamo_mode default --mixed_precision no --num_processes 1 --num_machines 1--num_cpu_threads_per_process 2 E:/SD_WIN/kohya_ss/sd-scripts/sdxl_train_network.py--config_file E:/SD_WIN/kohya_ss/outputs/config_lora-20240515-190738.toml
19:07:38-263218 INFO Command executed.
2024-05-15 19:08:39 INFO Loading settings from train_util.py:3744E:/SD_WIN/kohya_ss/outputs/config_lora-20240515-190738.toml...INFO E:/SD_WIN/kohya_ss/outputs/config_lora-20240515-190738 train_util.py:3763
2024-05-15 19:08:39 INFO prepare tokenizers sdxl_train_util.py:134
2024-05-15 19:08:41 INFO update token length: 75 sdxl_train_util.py:159INFO Using DreamBooth method. train_network.py:172INFO prepare images. train_util.py:1572INFO found directory C:\sdxl\1_images contains 8 image files train_util.py:1519WARNING No caption file found for 1 images. Training will continue without train_util.py:1550captions for these images. If class token exists, it will be used. /1枚の画像にキャプションファイルが見つかりませんでした。これらの画像についてはキャプションなしで学習を続行します。classtokenが存在する場合はそれを使います。WARNING C:\sdxl\1_images\videoplayback[(000859)2023-11-09-22-17-15].jpg train_util.py:1557INFO 8 train images with repeating. train_util.py:1613INFO 0 reg images. train_util.py:1616WARNING no regularization images / 正則化画像が見つかりませんでした train_util.py:1621INFO [Dataset 0] config_util.py:565batch_size: 1resolution: (1024, 1024)enable_bucket: Truenetwork_multiplier: 1.0min_bucket_reso: 256max_bucket_reso: 2048bucket_reso_steps: 64bucket_no_upscale: True[Subset 0 of Dataset 0]image_dir: "C:\sdxl\1_images"image_count: 8num_repeats: 1shuffle_caption: Falsekeep_tokens: 0keep_tokens_separator:secondary_separator: Noneenable_wildcard: Falsecaption_dropout_rate: 0.0caption_dropout_every_n_epoches: 0caption_tag_dropout_rate: 0.0caption_prefix: Nonecaption_suffix: Nonecolor_aug: Falseflip_aug: Falseface_crop_aug_range: Nonerandom_crop: Falsetoken_warmup_min: 1,token_warmup_step: 0,is_reg: Falseclass_tokens: imagescaption_extension: .txtINFO [Dataset 0] config_util.py:571INFO loading image sizes. train_util.py:853
100%|██████████████████████████████████████████████████████████████████████████████████| 8/8 [00:00<00:00, 2025.13it/s]INFO make buckets train_util.py:859WARNING min_bucket_reso and max_bucket_reso are ignored if bucket_no_upscale is train_util.py:876set, because bucket reso is defined by image size automatically /bucket_no_upscaleが指定された場合は、bucketの解像度は画像サイズから自動計算されるため、min_bucket_resoとmax_bucket_resoは無視されますINFO number of images (including repeats) / train_util.py:905各bucketの画像枚数(繰り返し回数を含む)INFO bucket 0: resolution (1024, 1024), count: 8 train_util.py:910INFO mean ar error (without repeats): 0.0 train_util.py:915WARNING clip_skip will be unexpected / SDXL学習ではclip_skipは動作しません sdxl_train_util.py:343INFO preparing accelerator train_network.py:225
accelerator device: cudaINFO loading model for process 0/1 sdxl_train_util.py:30INFO load StableDiffusion checkpoint: sdxl_train_util.py:70E:/SD_WIN/stable-diffusion-webui/models/Stable-diffusion/sd_xl_base_1.0.safetensors
2024-05-15 19:08:47 INFO building U-Net sdxl_model_util.py:192INFO loading U-Net from checkpoint sdxl_model_util.py:196
2024-05-15 19:11:37 INFO U-Net: <All keys matched successfully> sdxl_model_util.py:202
2024-05-15 19:11:38 INFO building text encoders sdxl_model_util.py:205
2024-05-15 19:11:41 INFO loading text encoders from checkpoint sdxl_model_util.py:258
2024-05-15 19:11:47 INFO text encoder 1: <All keys matched successfully> sdxl_model_util.py:272
2024-05-15 19:12:15 INFO text encoder 2: <All keys matched successfully> sdxl_model_util.py:276INFO building VAE sdxl_model_util.py:279
2024-05-15 19:12:19 INFO loading VAE from checkpoint sdxl_model_util.py:284
2024-05-15 19:12:23 INFO VAE: <All keys matched successfully> sdxl_model_util.py:287
2024-05-15 19:12:36 INFO Enable xformers for U-Net train_util.py:2660
import network module: networks.lora
2024-05-15 19:12:40 INFO [Dataset 0] train_util.py:2079INFO caching latents. train_util.py:974INFO checking cache validity... train_util.py:984
100%|████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:00<?, ?it/s]INFO caching latents... train_util.py:1021
100%|████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:37<00:00, 4.75s/it]
2024-05-15 19:13:19 INFO create LoRA network. base dim (rank): 8, alpha: 1 lora.py:810INFO neuron dropout: p=None, rank dropout: p=None, module dropout: p=None lora.py:811INFO create LoRA for Text Encoder 1: lora.py:902INFO create LoRA for Text Encoder 2: lora.py:902
2024-05-15 19:13:20 INFO create LoRA for Text Encoder: 264 modules. lora.py:910INFO create LoRA for U-Net: 722 modules. lora.py:918INFO enable LoRA for text encoder lora.py:961INFO enable LoRA for U-Net lora.py:966
prepare optimizer, data loader etc.
2024-05-15 19:13:24 INFO use 8-bit AdamW optimizer | {} train_util.py:3889
Traceback (most recent call last):File "E:\SD_WIN\kohya_ss\sd-scripts\sdxl_train_network.py", line 185, in <module>trainer.train(args)File "E:\SD_WIN\kohya_ss\sd-scripts\train_network.py", line 429, in trainunet = accelerator.prepare(unet)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\accelerate\accelerator.py", line 1213, in prepareresult = tuple(File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\accelerate\accelerator.py", line 1214, in <genexpr>self._prepare_one(obj, first_pass=True, device_placement=d) for obj, d in zip(args, device_placement)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\accelerate\accelerator.py", line 1094, in _prepare_onereturn self.prepare_model(obj, device_placement=device_placement)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\accelerate\accelerator.py", line 1334, in prepare_modelmodel = model.to(self.device)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\torch\nn\modules\module.py", line 1160, in toreturn self._apply(convert)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\torch\nn\modules\module.py", line 810, in _applymodule._apply(fn)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\torch\nn\modules\module.py", line 810, in _applymodule._apply(fn)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\torch\nn\modules\module.py", line 810, in _applymodule._apply(fn)[Previous line repeated 6 more times]File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\torch\nn\modules\module.py", line 833, in _applyparam_applied = fn(param)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\torch\nn\modules\module.py", line 1158, in convertreturn t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 50.00 MiB. GPU 0 has a total capacty of 4.00 GiB of which 0 bytes is free. Of the allocated memory 10.68 GiB is allocated by PyTorch, and 226.95 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Traceback (most recent call last):File "C:\Python310\lib\runpy.py", line 196, in _run_module_as_mainreturn _run_code(code, main_globals, None,File "C:\Python310\lib\runpy.py", line 86, in _run_codeexec(code, run_globals)File "E:\SD_WIN\kohya_ss\venv\Scripts\accelerate.EXE\__main__.py", line 7, in <module>File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\accelerate\commands\accelerate_cli.py", line 47, in mainargs.func(args)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\accelerate\commands\launch.py", line 1017, in launch_commandsimple_launcher(args)File "E:\SD_WIN\kohya_ss\venv\lib\site-packages\accelerate\commands\launch.py", line 637, in simple_launcherraise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['E:\\SD_WIN\\kohya_ss\\venv\\Scripts\\python.exe', 'E:/SD_WIN/kohya_ss/sd-scripts/sdxl_train_network.py', '--config_file', 'E:/SD_WIN/kohya_ss/outputs/config_lora-20240515-190738.toml']' returned non-zero exit status 1.
19:16:29-337912 INFO Training has ended.二、ComfyUI之插件Lora-Training-in-Comfy(https://github.com/LarryJane491/Lora-Training-in-Comfy.git),顺道也安装一下Image-Captioning-in-ComfyUI(https://github.com/LarryJane491/Image-Captioning-in-ComfyUI.git)和Vector_Sculptor_ComfyUI(https://github.com/Extraltodeus/Vector_Sculptor_ComfyUI.git)
在“custom_nodes”下clone它下来,重启安装,一般大概率是没法顺顺利利的,自行安装一些库,我这边列一下xformers和pytorch几个需要注意的库,其他的随意吧
accelerate 0.29.3
library 0.0.0 E:\SD_WIN\ComfyUI_windows_portable\ComfyUI\custom_nodes\Lora-Training-in-Comfy\sd-scripts
torch 2.3.0+cu121
torchaudio 2.3.0+cu121
torchvision 0.18.0+cu121
xformers 0.0.26.post1xformers优先安装,使用
{venv}/Scripts/pip.exe install xformers --index-url --index-url https://download.pytorch.org/whl/cu121
然后根据pytorch的版本提示安装torchaudio和torchvision我的例子:{venv}/Scripts/pip.exe install xformers==0.0.26.post1 torch==2.3.0+cu121 torchaudio==2.3.0+cu121 torchvision==0.18.0+cu121 --index-url https://download.pytorch.org/whl/cu121
其次要到“custom_nodes/Lora-Training-in-Comfy/sd-scripts/library”目录下运行
{venv}/Scripts/pip.exe install -e .后面这一步没做的话,可能会遇到library模块加不来,要是直接用线上的安装就傻眼了,大概率是对不上号的。
重新双击run_nvidia_gpu.bat运行ComfyUI,添加节点“LJRE/LORA/LORA training in ComfyUI”,SD1.5的LORA只需要改三个配置就可以运行了。
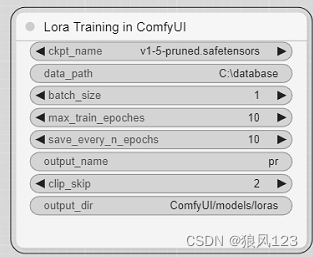
output_dir最好是相对run_nvidia_gpu.bat所在的路径,这样得到的lora不需要复制,重启ComfyUI就可以测试。
这个插件有个大问题,就是很多机器没法正常运行,哈哈,没错,是真的。我建议有两点:
1.更新sd-scripts,将原来删了,在同路径下运行
git clone https://github.com/kohya-ss/sd-scripts.git安装参考上面
2.修改train.py。 搜索"python -m accelerate",改为“{vevn-path}/python.exe -m accelerate”,vevn-path应该是run_nvidia_gpu.bat同目录下的python_embeded的绝对路径。(注:下载一键安装包,要是clone的版本应该自己知道venv路径的)
最后补充一张根据图片提取文本的流程图
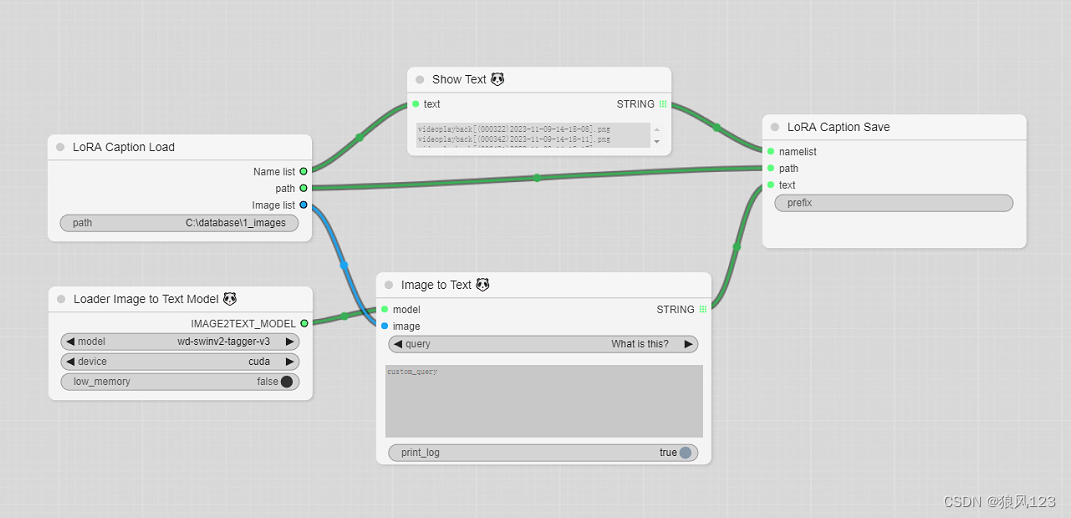
用到Comfyui_image2prompt(https://github.com/zhongpei/Comfyui_image2prompt.git),这玩意要是完整几乎不太可能,低端机器下wd-swinv2-tagger-v3-hf足够了。等有空再聊聊这个插件的安装经历。
当然也可以安装其他的插件代替的,WD14是不太可能了,还有其他的插件可以考虑。